
SpringCloud

SpringCloud
李阳知不可乎骤得,托遗响于悲风。 —— 苏轼《赤壁赋》
一、前置课程
1、MybatisPlus
1.1 项目启动
导入起步依赖
<!―-MybatisPlus-->
<dependency>
<groupId>com.baomidou</grouprd>
<artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.3.1</version>
</ dependency>自义定
Mapper继承MyBatisPlus提供的BaseMapper接口,并且指定实体类泛型eg:
public interface UserMapper extends BaseMapper<User> {}
1.2 常用注解
约定大于配置
@TableName:用来指定表名@Table: 用来指定表中主键字段信息@TableField:用来指定表中的普通字段信息

使用@TableField注解的常见场景
- 成员变量名与数据库字段名不一致
- 成员变量名以is开头且是布尔值
- 成员变量名与数据库关键字冲突
- 成员变量不是数据库字段
1.3 常见配置
mybatis-plus: |
1.4 核心功能
模糊查询
//查询名字中带o,balance>1000的id,user等 |
条件更新
// 更新用户名为jack的的余额为2000元 |
条件更新
// 更新id为1,2,4的用户余额扣100 |
自定义SQL
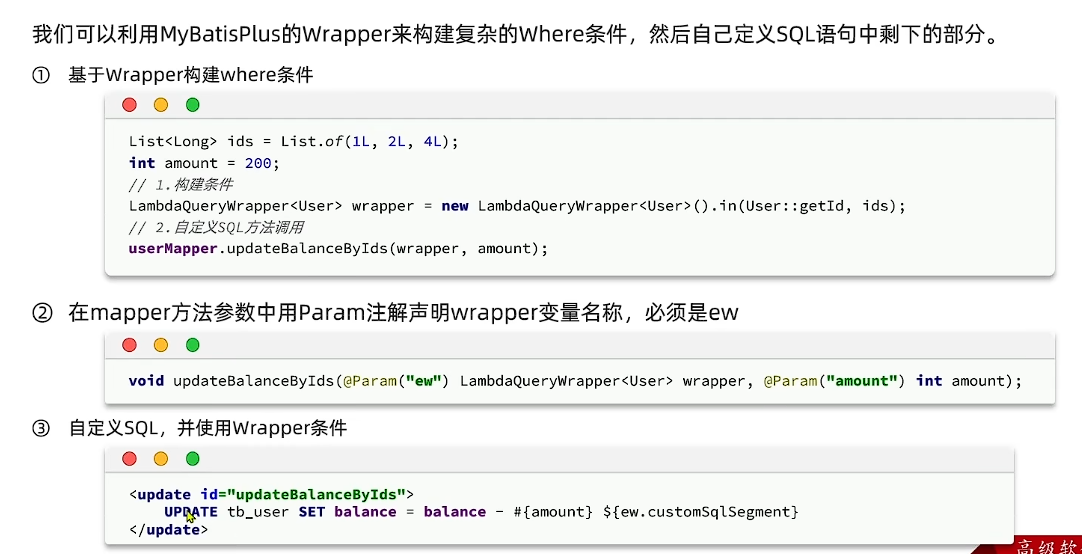
我们可以利用MyBatisPlus的Wrapper来构建复杂的Where条件,然后自己定义SQL语句中剩下的部分。
- 基于Wrapper构建where条件
- 在mapper方法参数中用Param注解声明wrapper变量名称,必须是ew
- 自定义SQL,并且使用wrapper条件
Service接口–IService
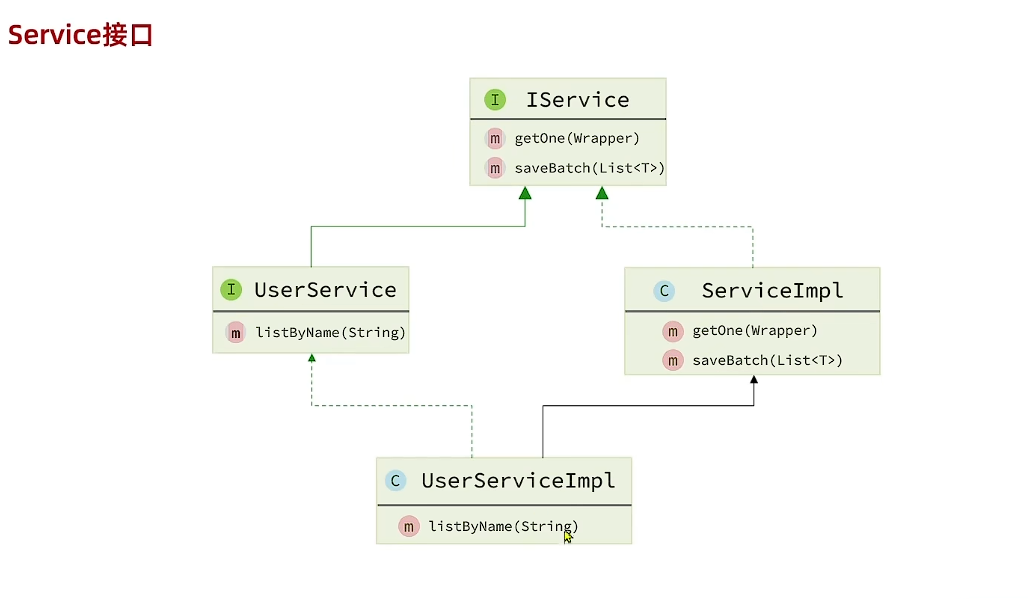
自定义Service去继承Iservice(要指定实体泛型),自定义ServiceImpl去继承ServiceImpl(要指定Mapper泛型和实体泛型)
eg:
public interface IUserserice extends IService<User> {} |
public class UserServiceImpl extends ServigeImpl<UserMapper,User> implements TUserService {} |
1.5 Restful风格接口
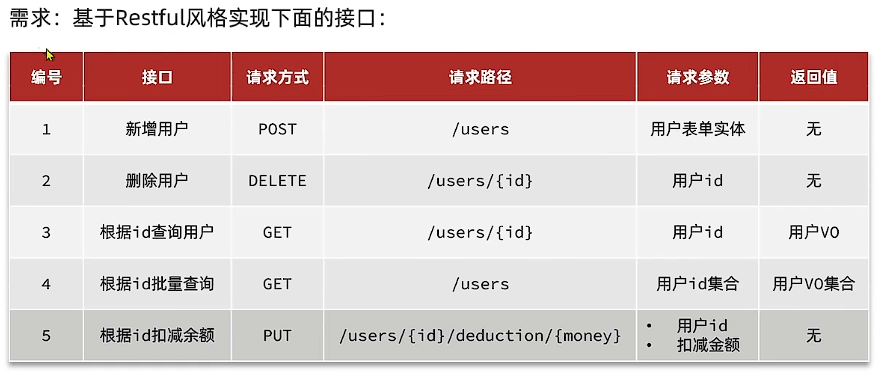
后端传给前端要定义VO,前端传给后端定义DTO
这里有一个我之前没有注意的点,po要转为vo,可以使用hutool工具包进行拷贝
BeanUtil.copyproperties(原始实体,目标实体) |
1.6 逻辑删除

1.7 枚举处理器
- 在枚举类的值上添加
@EnumValue注解

配置全局枚举处理器
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
1.8 JSON类型处理器
- 首先定义一个单独的JSON实体

- 然后将User类的info字段修改为UserInfo类型,并声明类型处理器:

- 在类上开启自动映射(这里设置autoResultMap = true是因为MyBatis-Plus对于这种类中再嵌套一个自定义类的,是需要手动在.xml中定义相关字段等,或者像这样开启自动映射)

1.9 分页插件
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。 所以,我们必须配置分页插件。
新建MybatisConfig.java
|
编写分页查询的测试
|
也可以支持排序(根据balance排序,false是降序)
int pageNo = 1, pageSize = 5; |
通用分页查询案例

定义一个统一的分页查询条件的实体,包含分页、排序参数、过滤条件
public class PageQuery {
private Long pageNo;
private Long pageSize;
private String sortBy;
private Boolean isAsc;
}然后让我们需要分页的实体去继承分页实体
callSuper = true根据子类自身的字段值和从父类继承的字段值 来生成hashcode,当两个子类对象比较时,只有子类对象的本身的字段值和继承父类的字段值都相同,equals方法的返回值是true@EqualsAndHashCode用于自动生成 equals() 和 hashCode() 方法,并且在比较时,调用父类(super)的 equals() 和 hashCode() 方法
public class UserQuery extends PageQuery {
private String name;
private Integer status;
private Integer minBalance;
private Integer maxBalance;
}新建统一返回结果集
public class PageDTO<T> {
private Long total;
private Long pages;
private List<T> list;
}分页查询代码示例
public PageDTO<UserVO> queryUsersPage(PageQuery query) {
// 1.构建条件
// 1.1.分页条件
Page<User> page = Page.of(query.getPageNo(), query.getPageSize());
// 1.2.排序条件
if (query.getSortBy() != null) {
page.addOrder(new OrderItem(query.getSortBy(), query.getIsAsc()));
}else{
// 默认按照更新时间排序
page.addOrder(new OrderItem("update_time", false));
}
// 2.查询
page(page);
// 3.数据非空校验
List<User> records = page.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return new PageDTO<>(page.getTotal(), page.getPages(), Collections.emptyList());
}
// 4.有数据,转换
List<UserVO> list = BeanUtil.copyToList(records, UserVO.class);
// 5.封装返回
return new PageDTO<UserVO>(page.getTotal(), page.getPages(), list);
}
将分页条件封装在工具类中
PageQuery
|
PageDTO
package com.itheima.mp.domain.dto; |
业务层代码可简化为
|
2.Docker
1. 安装问题
1. 解决配置网络时es33显示被已拔出问题
在电脑服务中开启VMware DHCP Service”和“VMware NAT Service”。即可
2. 解决Docker镜像问题
操她奶奶的,你妹的傻鸟Docker,用老师安装的方式一直不成功,最终在评论区找到答案
无法安装docker 建议直接:bash <(curl -sSL https://linuxmirrors.cn/docker.sh) 这条命令,一次性全安装完毕 |
2. 安装MySQL
docker run -d \ |
tee /etc/docker/daemon.json <<-'EOF' |
3. Docker常见命令

| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker images | 查看本地镜像 | docker images |
| docker rmi | 删除本地镜像 | docker rmi |
| docker run | 创建并运行容器(不能重复创建) | docker run |
| docker stop | 停止指定容器 | docker stop |
| docker start | 启动指定容器 | docker start |
| docker restart | 重新启动容器 | docker restart |
| docker rm | 删除指定容器 | docs.docker.com |
| docker ps | 查看容器 | docker ps |
| docker logs | 查看容器运行日志 | docker logs |
| docker exec | 进入容器 | docker exec |
| docker save | 保存镜像到本地压缩文件 | docker save |
| docker load | 加载本地压缩文件到镜像 | docker load |
| docker inspect | 查看容器详细信息 | docker inspect |
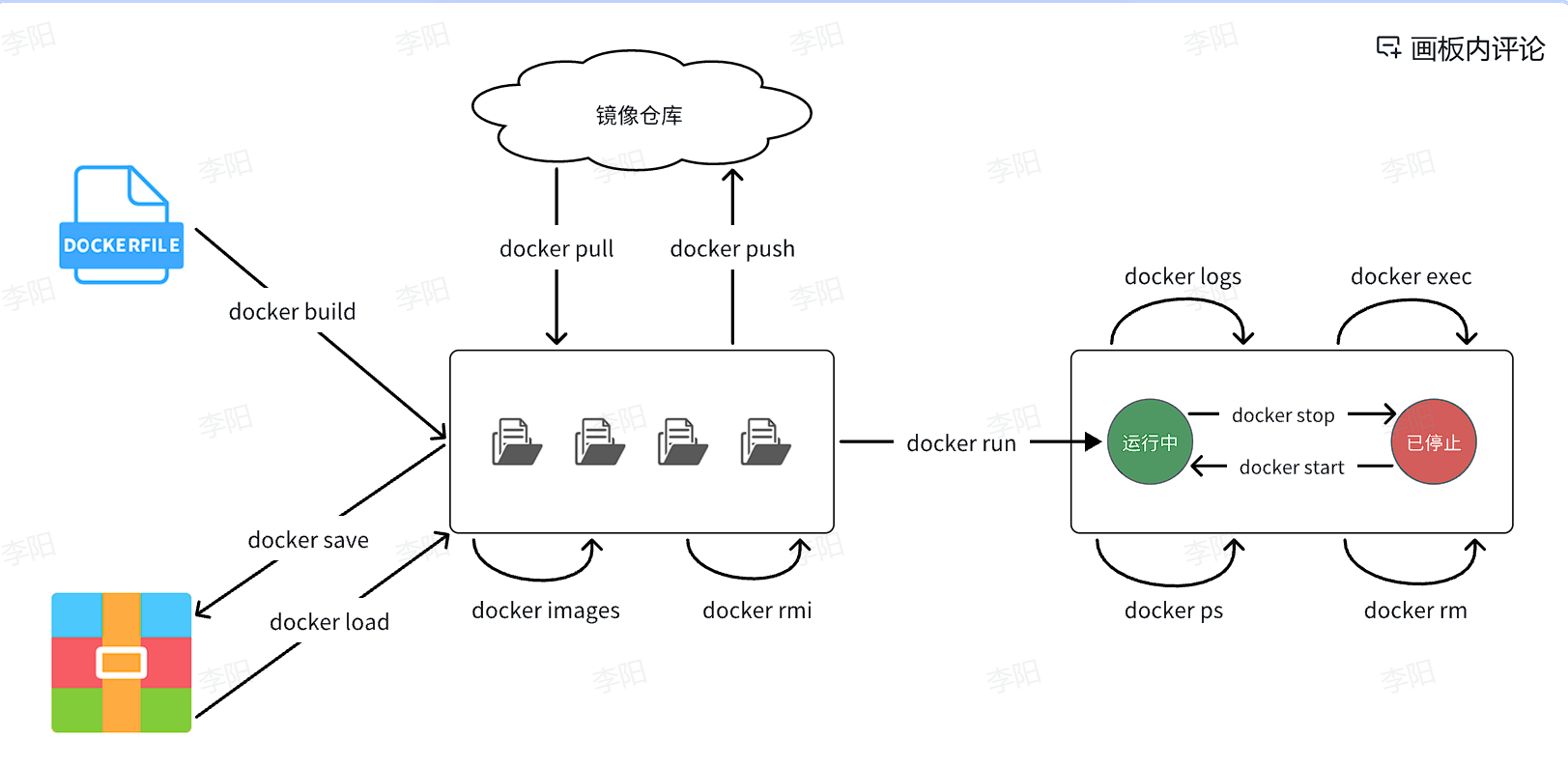
如何把镜像交给运维人员:1.使用docker save形成本地压缩包,运维人员再使用docker load将本地这个压缩包进行解压;2.将镜像推送到镜像仓库,运维人员再从镜像仓库进行拉取
4. 数据卷
容器是隔离环境,容器内程序的文件、配置、运行时产生的容器都在容器内部,我们要读写容器内的文件非常不方便。大家思考几个问题:
- 如果要升级MySQL版本,需要销毁旧容器,那么数据岂不是跟着被销毁了?
- MySQL、Nginx容器运行后,如果我要修改其中的某些配置该怎么办?
- 我想要让Nginx代理我的静态资源怎么办?
因此,容器提供程序的运行环境,但是程序运行产生的数据、程序运行依赖的配置都应该与容器解耦。
4.1 什么是数据卷
数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。(ps:其实类似于双向绑定,修改数据卷里面的nginx内容,实际的nginx的内容也会修改)
以Nginx为例,我们知道Nginx中有两个关键的目录:
html:放置一些静态资源conf:放置配置文件
如果我们要让Nginx代理我们的静态资源,最好是放到html目录;如果我们要修改Nginx的配置,最好是找到conf下的nginx.conf文件。
但遗憾的是,容器运行的Nginx所有的文件都在容器内部。所以我们必须利用数据卷将两个目录与宿主机目录关联,方便我们操作。如图:
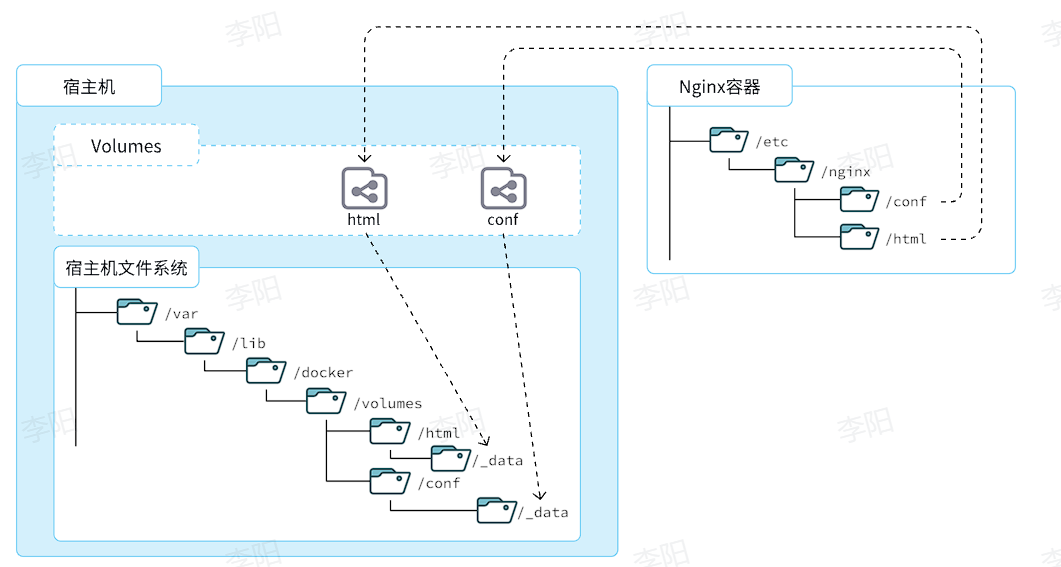
在上图中:
- 我们创建了两个数据卷:
conf、html - Nginx容器内部的
conf目录和html目录分别与两个数据卷关联。 - 而数据卷conf和html分别指向了宿主机的
/var/lib/docker/volumes/conf/_data目录和/var/lib/docker/volumes/html/_data目录
这样以来,容器内的conf和html目录就 与宿主机的conf和html目录关联起来,我们称为挂载。此时,我们操作宿主机的/var/lib/docker/volumes/html/_data就是在操作容器内的/usr/share/nginx/html/_data目录。只要我们将静态资源放入宿主机对应目录,就可以被Nginx代理了。
4.2 数据卷的命令
| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker volume create | 创建数据卷 | docker volume create |
| docker volume ls | 查看所有数据卷 | docs.docker.com |
| docker volume rm | 删除指定数据卷 | docs.docker.com |
| docker volume inspect | 查看某个数据卷的详情 | docs.docker.com |
| docker volume prune | 清除数据卷 | docker volume prune |
注意:容器与数据卷的挂载要在创建容器时配置,对于创建好的容器,是不能设置数据卷的。而且创建容器的过程中,数据卷会自动创建。
如何挂载数据卷?
- 在创建容器时,利用-v数据卷名:容器内目录完成挂载
- 容器创建时,如果发现挂载的数据卷不存在时,会自动创建
4.3 创建Nginx 数据卷
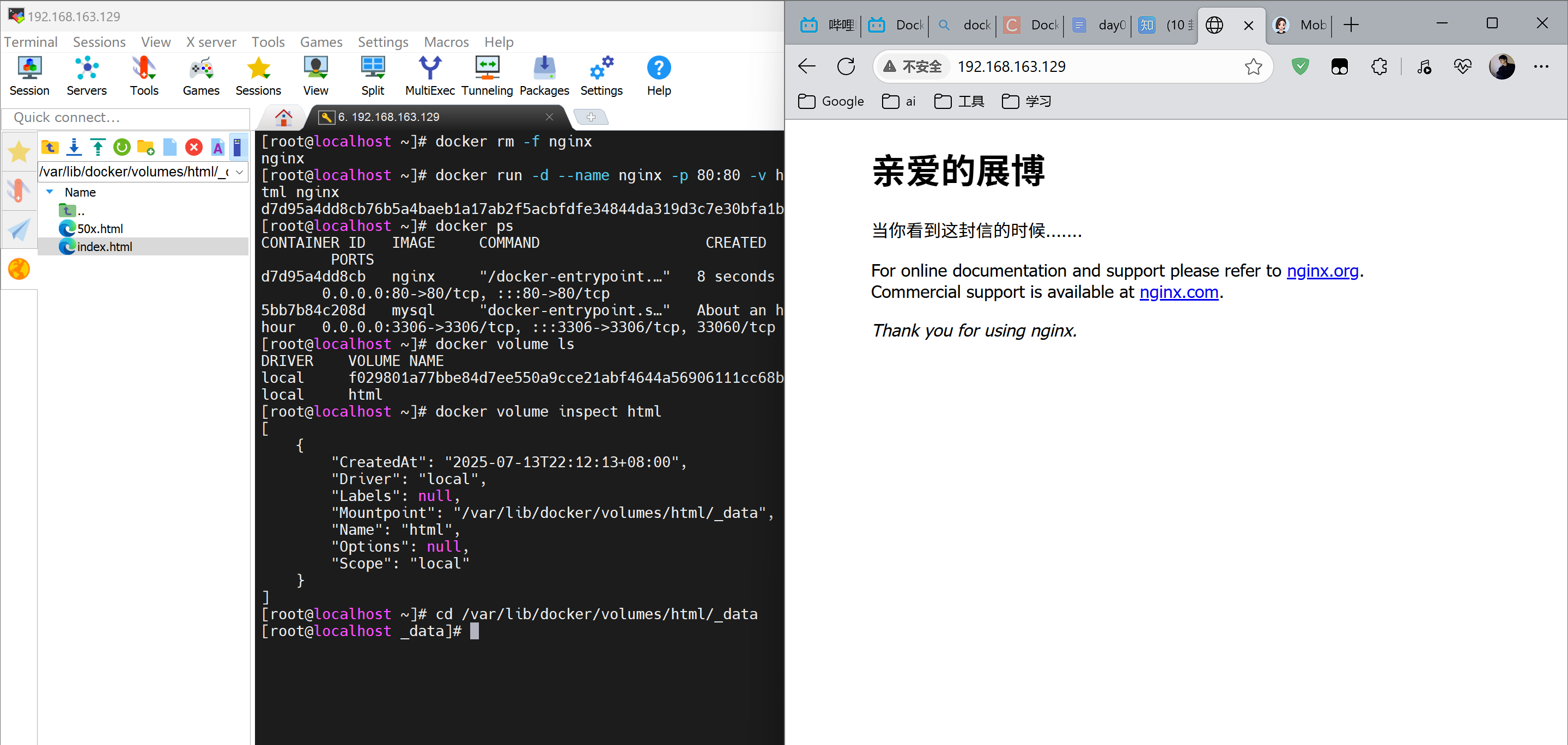 哇神奇
哇神奇
[root@localhost ~]# docker rm -f nginx |
这是 Docker 的默认存储位置,所有命名卷都会存放在 /var/lib/docker/volumes/<卷名>/_data 下
volume对应的宿主机目录,html是虚拟目录 ,/usr/share/nginx/html 容器内的对应目录

4.4 MySQL 容器的数据挂载
[root@localhost ~]# docker inspect mysql |
发现有默认的数据挂载,但是默认匿名挂载名字复杂目录太深了,下面给他修改到挂载到根目录
docker run -d \ |
注意:SQL文件必须要有创建数据库的命令,不然无法创建成功数据库
然后将SQL文件放在init文件夹里面
运行
docker run -d \ |
即可
5. 自定义镜像
镜像就是包含了应用程序、程序运行的系统函数库、运行配置等文件的文件包。构建镜像的过程其实就是把上述文件打包的过程。
由于制作镜像的过程中,需要逐层处理和打包,比较复杂,所以Docker就提供了自动打包镜像的功能。我们只需要将打包的过程,每一层要做的事情用固定的语法写下来,交给Docker去执行即可。而这种记录镜像结构的文件就称为Dockerfile
| 指令 | 说明 | 示例 |
|---|---|---|
| FROM | 指定基础镜像 | FROM centos:6 |
| ENV | 设置环境变量,可在后面指令使用 | ENV key value |
| COPY | 拷贝本地文件到镜像的指定目录 | COPY ./xx.jar /tmp/app.jar |
| RUN | 执行Linux的shell命令,一般是安装过程的命令 | RUN yum install gcc |
| EXPOSE | 指定容器运行时监听的端口,是给镜像使用者看的 | EXPOSE 8080 |
| ENTRYPOINT | 镜像中应用的启动命令,容器运行时调用 | ENTRYPOINT java -jar xx.jar |
6. 网络
容器的网络IP其实是一个虚拟的IP,其值并不固定与某一个容器绑定,如果我们在开发时写死某个IP,而在部署时很可能MySQL容器的IP会发生变化,连接会失败。
所以,我们必须借助于docker的网络功能来解决这个问题 常见命令
| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker network create | 创建一个网络 | docker network create |
| docker network ls | 查看所有网络 | docs.docker.com |
| docker network rm | 删除指定网络 | docs.docker.com |
| docker network prune | 清除未使用的网络 | docs.docker.com |
| docker network connect | 使指定容器连接加入某网络 | docs.docker.com |
| docker network disconnect | 使指定容器连接离开某网络 | docker network disconnect |
| docker network inspect | 查看网络详细信息 | docker network inspect |
[root@localhost mysql]# docker network ls |
7.使用Docker打包项目(tlias为例)
老东西 终于把焚决交出来了
7.1后端打包
准备MySQL容器,并且创建tlias数据库以及表结构(上面在本地目录挂载MySQL时已经2完成)
准备Java应用(tlias)镜像,部署Docker容器,运行测试
修改tlias项目的配置文件,修改数据库服务地址及logback日志文件存放地址,打jar包。
编写Dockerfile文件。
构建Docker镜像。
部署Docker容器。
具体步骤
打开idea将yml中数据库连接部分改为Docker中的MySQL
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://mysql:3306/tlias?useUnicode=true&characterEncoding=utf-8&useSSL=true
username: root
password: abc123在idea中的Maven中的Lifecycle中点击
package,等待build成功。然后我们的target文件夹中会出现我们的Jar包了。jar包名字很长可以适当重命名新建Dockerfile
# 使用 CentOS 7 作为基础镜像
FROM centos:7
# 添加 JDK 到镜像中
COPY jdk21.tar.gz /usr/local/
RUN tar -xzf /usr/local/jdk21.tar.gz -C /usr/local/ && rm /usr/local/jdk21.tar.gz
# 设置环境变量
ENV JAVA_HOME=/usr/local/jdk-21.0.1
ENV PATH=$JAVA_HOME/bin:$PATH
# 配置阿里云OSS
ENV OSS_ACCESS_KEY_ID=[你的]
ENV OSS_ACCESS_KEY_SECRET=[你的]
#统一编码
ENV LANG=en_US.UTF-8
ENV LANGUAGE=en_US:en
ENV LC_ALL=en_US.UTF-8
# 创建应用目录
RUN mkdir -p /tlias
WORKDIR /tlias
# 复制应用 JAR 文件到容器
COPY tlias.jar tlias.jar
# 暴露端口
EXPOSE 8080
# 运行命令
ENTRYPOINT ["java","-jar","/tlias/tlias.jar"]在
/usr/local/下新建tlias-docker-app文件夹,里面上传进去我们的tlias.jar,Dockerfile,jdk21然后去构建Docker镜像
[root@localhost tlias-docker-app]# docker build -t tlias:1.0 .
[+] Building 266.8s (11/11) FINISHED docker:default
=> [internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 818B 0.0s
=> [internal] load metadata for docker.io/library/centos:7 146.9s
=> [internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [1/6] FROM docker.io/library/centos:7@sha256:be65f488b7764ad3638f23 111.2s
=> => resolve docker.io/library/centos:7@sha256:be65f488b7764ad3638f236b 0.0s
=> => sha256:eeb6ee3f44bd0b5103bb561b4c16bcb82328cfe5809 2.75kB / 2.75kB 0.0s
=> => sha256:2d473b07cdd5f0912cd6f1a703352c82b512407 76.10MB / 76.10MB 103.9s
=> => sha256:be65f488b7764ad3638f236b7b515b3678369a5124c 1.20kB / 1.20kB 0.0s
=> => sha256:dead07b4d8ed7e29e98de0f4504d87e8880d4347859d839 529B / 529B 0.0s
=> => extracting sha256:2d473b07cdd5f0912cd6f1a703352c82b512407db6b05b43 7.1s
=> [internal] load build context 0.0s
=> => transferring context: 173B 0.0s
=> [2/6] COPY jdk21.tar.gz /usr/local/ 2.0s
=> [3/6] RUN tar -xzf /usr/local/jdk21.tar.gz -C /usr/local/ && rm /usr 5.4s
=> [4/6] RUN mkdir -p /tlias 0.4s
=> [5/6] WORKDIR /tlias 0.0s
=> [6/6] COPY tlias.jar tlias.jar 0.1s
=> exporting to image 0.7s
=> => exporting layers 0.6s
=> => writing image sha256:8b8dd47f37a8752599c8d24b4b01dcce96ccb2469d4f4 0.0s
=> => naming to docker.io/library/tlias:1.0 0.0s
[root@localhost tlias-docker-app]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tlias 1.0 8b8dd47f37a8 About a minute ago 783MB
redis latest f2cd22713a18 7 days ago 128MB
nginx latest 9592f5595f2b 2 weeks ago 192MB
mysql latest 4c2531d6bf10 2 months ago 859MB取名字为tlias,版本1.0,在当前文件夹里
部署docker容器
[root@localhost tlias-docker-app]# docker run -d --name tlias-server -p 8080:8080 --network baskly tlias:1.0
ffc30c9fde8cf187b0c035e1fd27b12417ebcf988af34b3779c2cf50040f7a4d
[root@localhost tlias-docker-app]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ffc30c9fde8c tlias:1.0 "java -jar /tlias/tl…" 18 seconds ago Up 17 seconds 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp tlias-server使用
docker logs -f tlias-service查看后端启动日志[root tlias-docker-app]# docker logs -f tlias-server
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.4.4)
2025-07-13T21:02:32.843Z INFO 1 --- [tlias-web-managemen] [ main] c.itheima.TliasWebManagemenApplication : Starting TliasWebManagemenApplication v0.0.1-SNAPSHOT using Java 21.0.1 with PID 1 (/tlias/tlias.jar started by root in /tlias)
2025-07-13T21:02:32.849Z INFO 1 --- [tlias-web-managemen] [ main] c.itheima.TliasWebManagemenApplication : No active profile set, falling back to 1 default profile: "default"
2025-07-13T21:02:35.395Z INFO 1 --- [tlias-web-managemen] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port 8080 (http)
2025-07-13T21:02:35.427Z INFO 1 --- [tlias-web-managemen] [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2025-07-13T21:02:35.428Z INFO 1 --- [tlias-web-managemen] [ main] o.apache.catalina.core.StandardEngine : Starting Servlet engine: [Apache Tomcat/10.1.39]
2025-07-13T21:02:35.493Z INFO 1 --- [tlias-web-managemen] [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2025-07-13T21:02:35.495Z INFO 1 --- [tlias-web-managemen] [ main] w.s.c.ServletWebServerApplicationContext : Root WebApplicationContext: initialization completed in 2524 ms
Logging initialized using 'class org.apache.ibatis.logging.stdout.StdOutImpl' adapter.
,------. ,--. ,--. ,--.
| .--. ' ,--,--. ,---. ,---. | '--' | ,---. | | ,---. ,---. ,--.--.
| '--' | ' ,-. | | .-. | | .-. : | .--. | | .-. : | | | .-. | | .-. : | .--'
| | --' \ '-' | ' '-' ' \ --. | | | | \ --. | | | '-' ' \ --. | |
`--' `--`--' .`- / `----' `--' `--' `----' `--' | |-' `----' `--'
`---' `--' is intercepting.
2025-07-13T21:02:37.128Z INFO 1 --- [tlias-web-managemen] [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port 8080 (http) with context path '/'
2025-07-13T21:02:37.149Z INFO 1 --- [tlias-web-managemen] [ main] c.itheima.TliasWebManagemenApplication : Started TliasWebManagemenApplication in 5.209 seconds (process running for 5.838)这样我们的项目就启动成功了使用ApiFox发送请求也能正常输出结果

7.2. 前端项目部署
创建一个新的nginx容器,将资料中提供的前端项目的静态资源部署到nginx中。

在root文件夹下创建一个新文件夹用于映射Nginx,名字叫
tlias-nginx。然后配置挂载
docker run -d \
--name nginx-tlias \
-v /root/tlias-nginx/html:/usr/share/nginx/html \
-v /root/tlias-nginx/conf/nginx.conf:/etc/nginx/nginx.conf \
--network baskly \
-p 80:80 \
nginx:1.20.2然后访问(未开启需要开启一下服务)
# 安装ntpdate(若未安装)
sudo yum install -y ntpdate
# 同步阿里云时间服务器(北京时间)
sudo ntpdate ntp.aliyun.com解决因为Linux时间和系统系统不符导致的时区不同步问题
8. DockerCompose
老东西 把异火也交出来了
Docker Compose通过一个单独的docker-compose.yml模板文件(YANL 格式)来定义一组相关联的应用容器,帮助我们实现多个相互关联的Docker容器的快速部署。
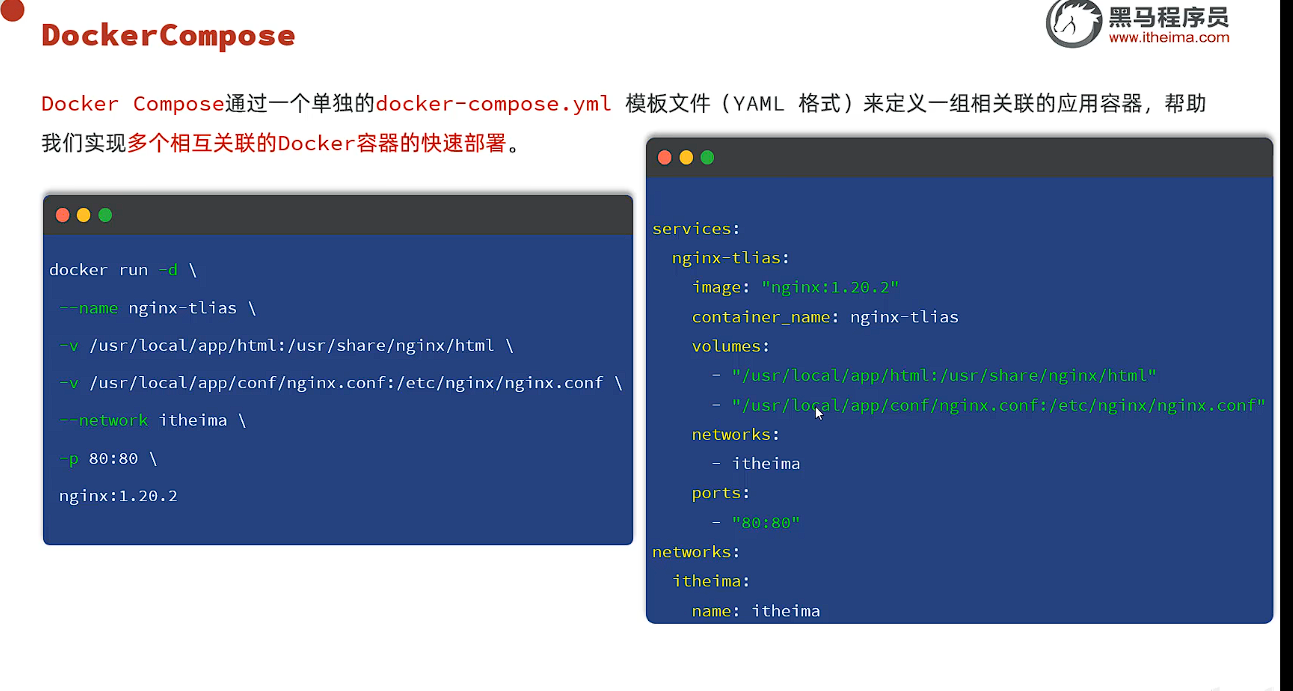
现在我们使用DockerCompose来重新构建项目
- 准备资源(tlias.sql,服务端的jdk17、jar包、Dockerfile,前端项目打包文件、nginx.conf)
- 准备docker-compose.yml配置文件
- 基于DockerCompose快速构建项目
services: |
根据compose定义的路径在文件夹下新建空文件夹,然后将以下文件存放在文件夹中

docker compose [OPTIONS] [COMMAND] |
其中,OPTIONS和COMMAND都是可选参数,比较常见的有:
| 类型 | 参数或指令 | 说明 |
|---|---|---|
| Options | -f | 指定compose文件的路径和名称 |
| -p | 指定project名称。project就是当前compose文件中设置的多个service的集合,是逻辑概念 | |
| Commands | up | 创建并启动所有service容器 |
| down | 停止并移除所有容器、网络 | |
| ps | 列出所有启动的容器 | |
| logs | 查看指定容器的日志 | |
| stop | 停止容器 | |
| start | 启动容器 | |
| restart | 重启容器 | |
| top | 查看运行的进程 | |
| exec | 在指定的运行中容器中执行命令 |
创建容器
[root@localhost app]# docker compose up -d
[+] Running 11/11
✔ mysql Pulled 94.0s
✔ 90dac1e734aa Already exists 0.0s
✔ bf40b60a847d Pull complete 32.0s
✔ 9d9cb66e1171 Pull complete 32.1s
✔ 31b29e08d2d1 Pull complete 32.8s
✔ 1f5a1dfb5b55 Pull complete 32.8s
✔ 7becd864c61c Pull complete 32.8s
✔ 00a0a1479659 Pull complete 35.0s
✔ cff841917be4 Pull complete 35.0s
✔ 8e98c1c43da6 Pull complete 76.4s
✔ 61ba5ff08093 Pull complete 76.4s
[+] Building 38.5s (11/11) FINISHED docker:default
=> [tlias internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 818B 0.0s
=> [tlias internal] load metadata for docker.io/library/centos:7 36.3s
=> [tlias internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [tlias 1/6] FROM docker.io/library/centos:7@sha256:be65f488b7764ad363 0.0s
=> [tlias internal] load build context 2.1s
=> => transferring context: 232.73MB 2.1s
=> CACHED [tlias 2/6] COPY jdk21.tar.gz /usr/local/ 0.0s
=> CACHED [tlias 3/6] RUN tar -xzf /usr/local/jdk21.tar.gz -C /usr/local 0.0s
=> CACHED [tlias 4/6] RUN mkdir -p /tlias 0.0s
=> CACHED [tlias 5/6] WORKDIR /tlias 0.0s
=> CACHED [tlias 6/6] COPY tlias.jar tlias.jar 0.0s
=> [tlias] exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:e2a98bd74211094262b8ba068f777e782edeba8b11cdf 0.0s
=> => naming to docker.io/library/app-tlias 0.0s
[+] Running 4/4
✔ Network itheima Created 0.1s
✔ Container mysql Started 1.2s
✔ Container tlias-server Started 1.2s
✔ Container nginx-tlias Started开始停止容器
[root@localhost app]# docker compose stop
[+] Stopping 3/3
✔ Container nginx-tlias Stopped 0.2s
✔ Container tlias-server Stopped 0.2s
✔ Container mysql Stopped 2.9s
[root@localhost app]# docker compose start
[+] Running 3/3
✔ Container mysql Started 0.3s
✔ Container tlias-server Started 0.3s
✔ Container nginx-tlias Started 0.4s
[root@localhost app]#🥲心心念念的Docker终于结束了
二、微服务01
1. 导入后端项目
导入后端项目启动项目时报了错误
java.lang.reflect.InaccessibleObjectException |
看弹幕说时因为MyBatisPlus版本与Java高版本冲突导致的反射问题
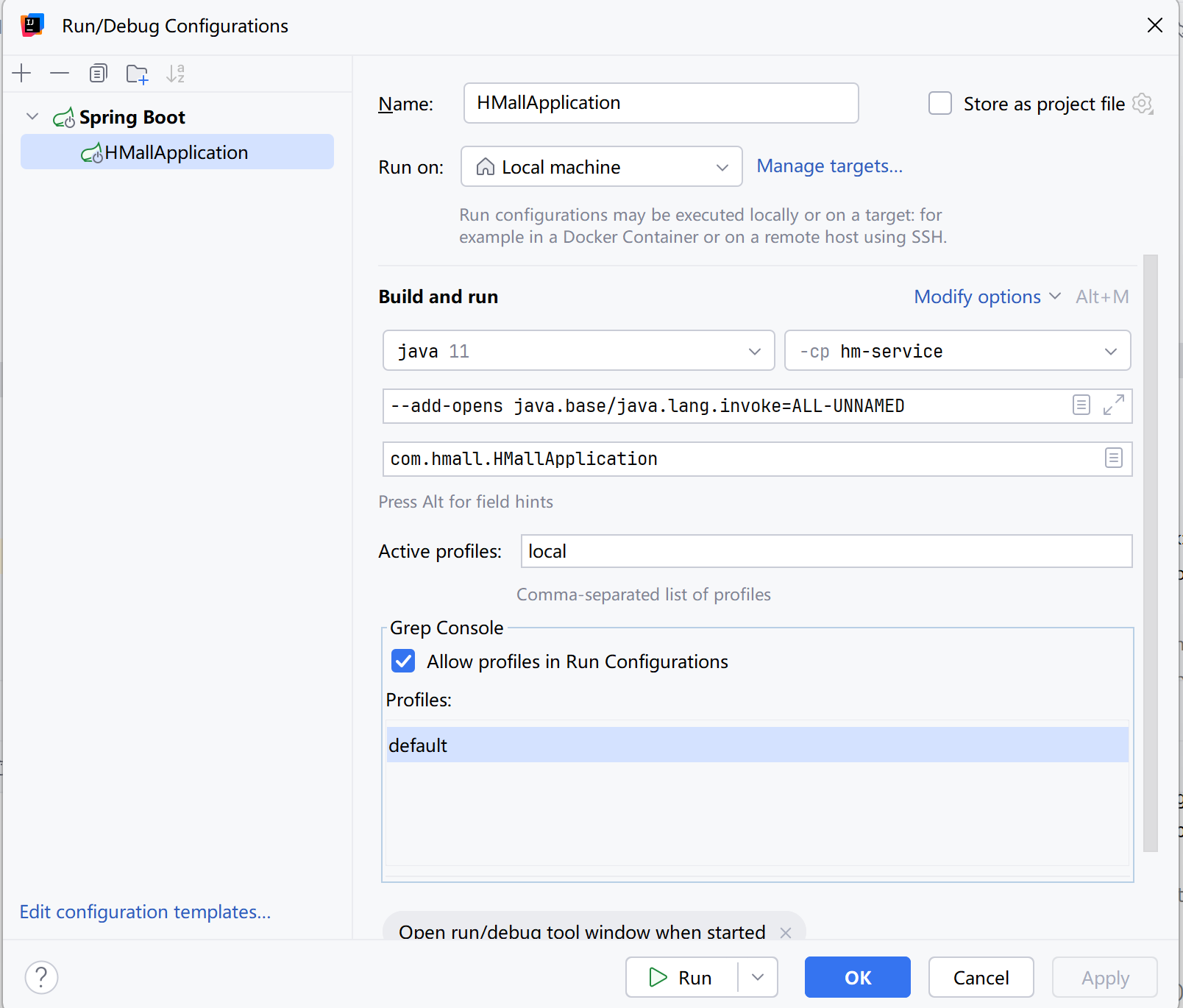
配置vm
--add-opens java.base/java.lang.invoke=ALL-UNNAMED |
即可解决
解决时区不同步问题
[root@localhost ~]# date |
2. 单体架构与微服务
单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。
优点:架构简单,部署成本低
缺点:团队协作成本高,系统发布效率低,系统可用性差
微服务架构,是服务化思想指导下的一套最佳实践架构方案。服务化,就是把单体架构中的功能模块拆分为多个独立项目。
3. 微服务拆分原则

什么时候需要拆分微服务?
- 如果是创业型公司,最好先用单体架构快速迭代开发,验证市场运作模型,快速试错。当业务跑通以后,随着业务规模扩大、人员规模增加,再考虑拆分微服务。
- 如果是大型企业,有充足的资源,可以在项目开始之初就搭建微服务架构
如何拆分?
- 首先要做到高内聚、低耦合
- 从拆分方式来说,有横向拆分和纵向拆分两种。纵向就是按照业务功能模块,横向则是拆分通用性业务,提高复用性
服务拆分之后,不可避免的会出现跨微服务的业务,此时微服务之间就需要进行远程调用。微服务之间的远程调用被称为RPC,即远程过程调用。RPC的实现方式有很多,比如:
- 基于Http协议
- 基于Dubbo协议
我们使用的是Http方式,这种方式不关心服务提供者的具体技术实现,只要对外暴露Http接口即可,更符合微服务的需要。
4. 远程调用(RPC)
在拆分的时候,我们发现一个问题:就是购物车业务中需要查询商品信息,但商品信息查询的逻辑全部迁移到了item-service服务,导致我们无法查询。
最终结果就是查询到的购物车数据不完整,因此要想解决这个问题,我们就必须改造其中的代码,把原本本地方法调用,改造成跨微服务的远程调用(RPC,即Remote Produce Call)。
因此,现在查询购物车列表的流程变成了这样:
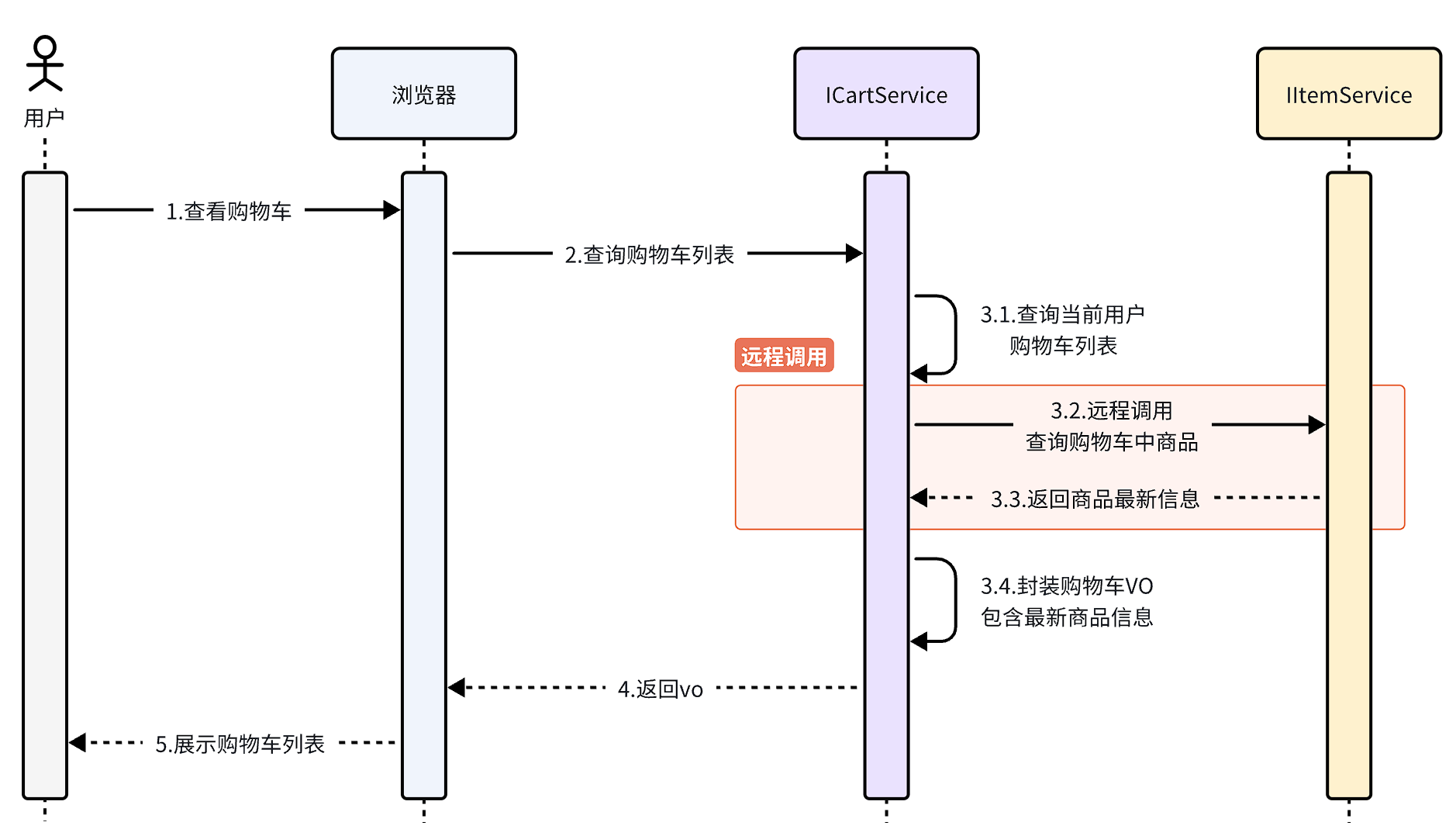
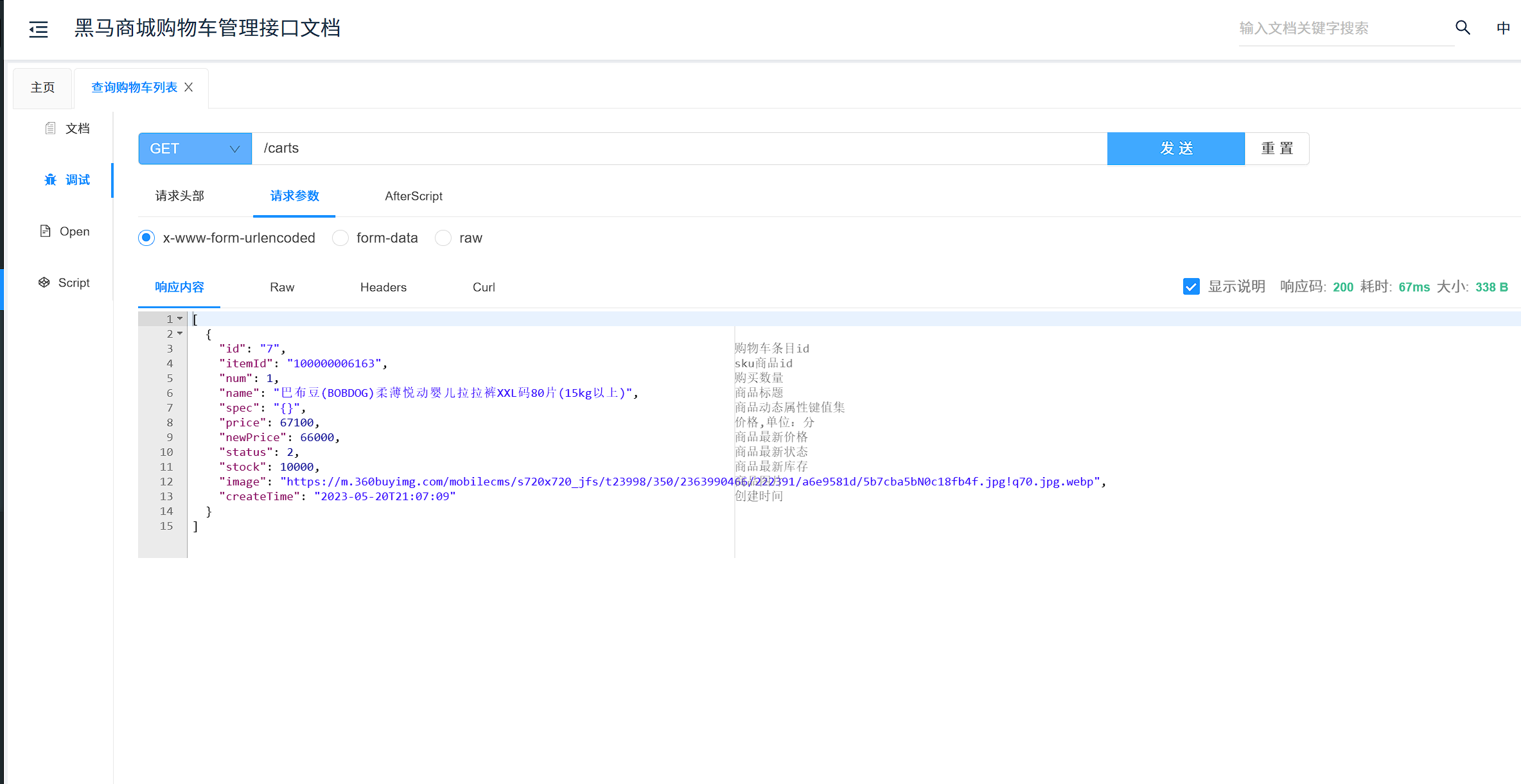
那么问题来了:我们该如何跨服务调用,准确的说,如何在cart-service中获取item-service服务中的提供的商品数据呢?
答案是肯定的,我们前端向服务端查询数据,其实就是从浏览器远程查询服务端数据。比如我们刚才通过Swagger测试商品查询接口,就是向http://localhost:8081/items这个接口发起的请求:
而这种查询就是通过http请求的方式来完成的,不仅仅可以实现远程查询,还可以实现新增、删除等各种远程请求。 那么:我们该如何用Java代码发送Http的请求呢?
4.1 RestTemplate
Java发送http请求可以使用Spring提供的RestTemplate,使用的基本步骤如下:
- 注册RestTemplate到Spring容器
- 调用RestTemplate的API发送请求,常见方法有:
- getForObject:发送Get请求并返回指定类型对象
- PostForObject:发送Post请求并返回指定类型对象
- put:发送PUT请求
- delete:发送Delete请求
- exchange:发送任意类型请求,返回ResponseEntity
感觉这种如果有大量用户同时请求不会变的很卡吗??????
构造器注入
Spring推荐我们使用Lombok构造器注入而不是使用@Autowired
因此我们可以在类上添加@RequiredArgsConstructor注解,使用final注入类
eg:

4.2 注册中心
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如
item-service - 服务消费者:调用其它微服务提供的接口,比如
cart-service - 服务者可以是消费者,消费者也可以是服务者
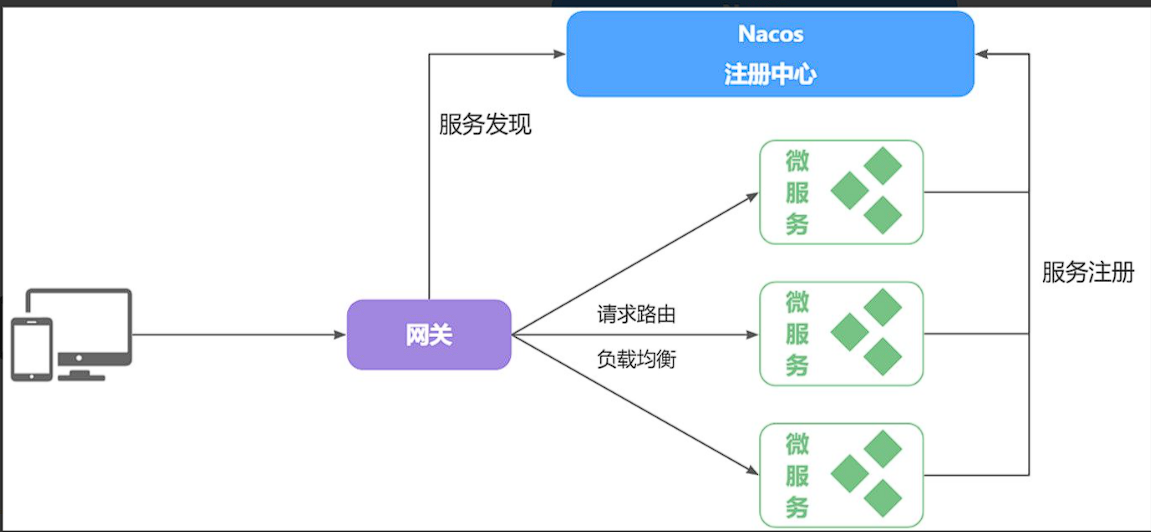
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。注册中心、服务提供者、服务消费者三者间关系如下:
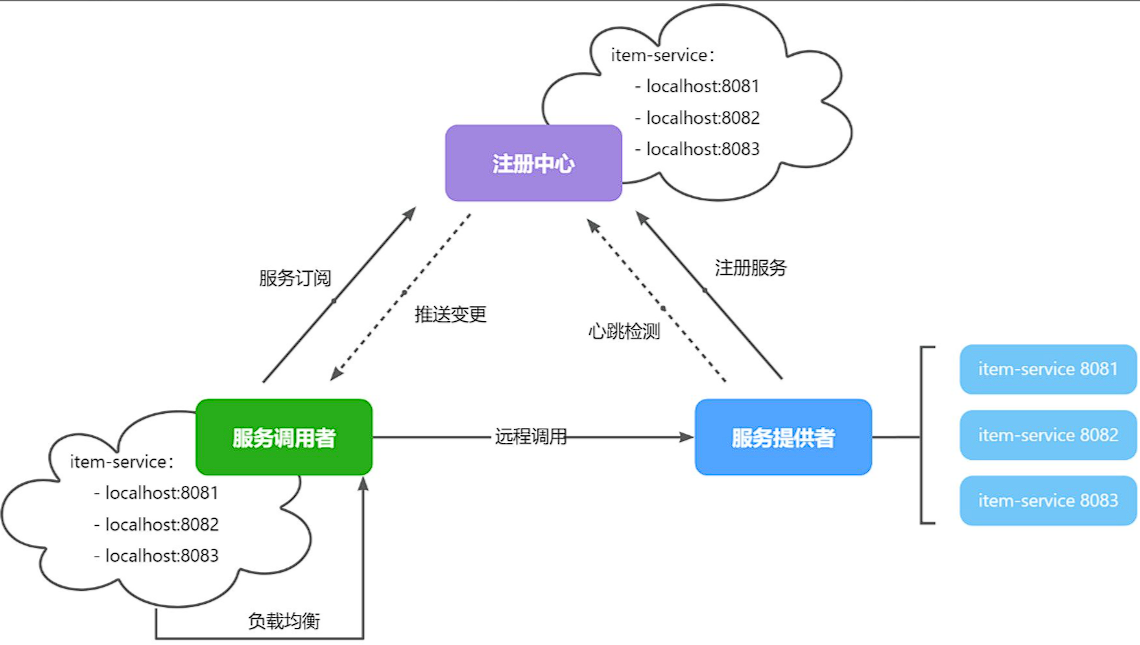
流程如下:
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 注册中心一旦认为某个实例宕机并将其剔除实例列表,那么其他服务的调用者就无法再调用这个实例。
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
4.3 Nacos注册中心
docker run -d \ |
访问路径
192.168.163.129:8848/nacos |
4.4 OpenFeign


哇神奇
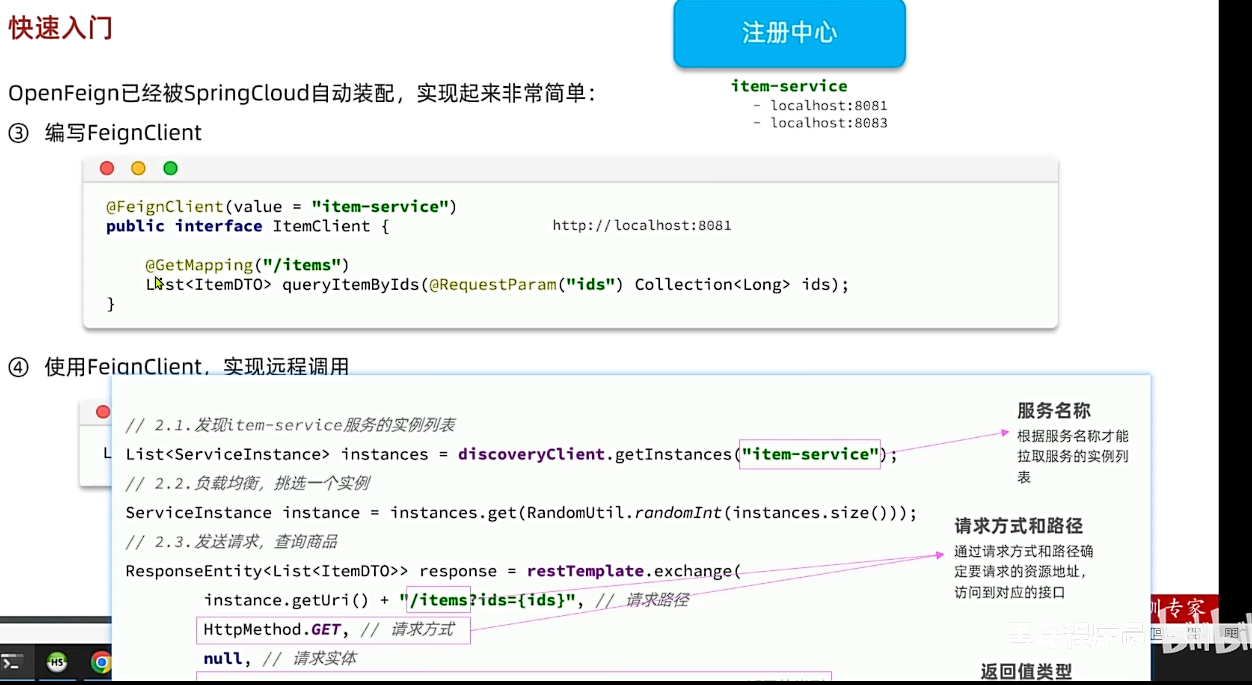
- 将来Feign可以根据服务名称去注册中心中去拉取实例列表
- Feign会使用负载均衡自动获取一个实例(我们在pom中引入了负载均衡的依赖了)
- 然后定义GET请求,路径为
/items,
4.5 连接池
连接池指的是一组预先创建的 HTTP 连接,这些连接可以被重复使用,而不是每次请求都创建一个新的连接。
在 Feign 中,不同的 HTTP 客户端实现对连接池的支持有所不同:
HttpURLConnection:
这是 Java 的默认 HTTP 客户端实现,不支持连接池。每次请求都会创建一个新的连接,请求完成后连接会被关闭。这种方式在高并发场景下性能较差。
Apache HttpClient:
这是一个功能强大的 HTTP 客户端库,支持连接池。通过配置连接池,可以复用连接,提高性能。
OKHttp:
这是另一个流行的 HTTP 客户端库,也支持连接池。OKHttp 的连接池实现高效且易于配置,适合在高并发场景下使用。
OpenFeign对Http请求做了优雅的伪装,不过其底层发起http请求,依赖于其它的框架。这些框架可以自己选择,包括以下三种:
- HttpURLConnection:默认实现,不支持连接池
- Apache Httpclient:支持连接池
- OKHttp:支持连接池
具体源码可以参考FeignBlockingLoadBalancerClient类中的delegate成员变量。
因此我们通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,我们使用OK Http
在cart-service的pom.xml中引入依赖:
<!--OK http 的依赖 --> |
在cart-service的application.yml配置文件中开启Feign的连接池功能:
feign: |
4.6 最佳实践
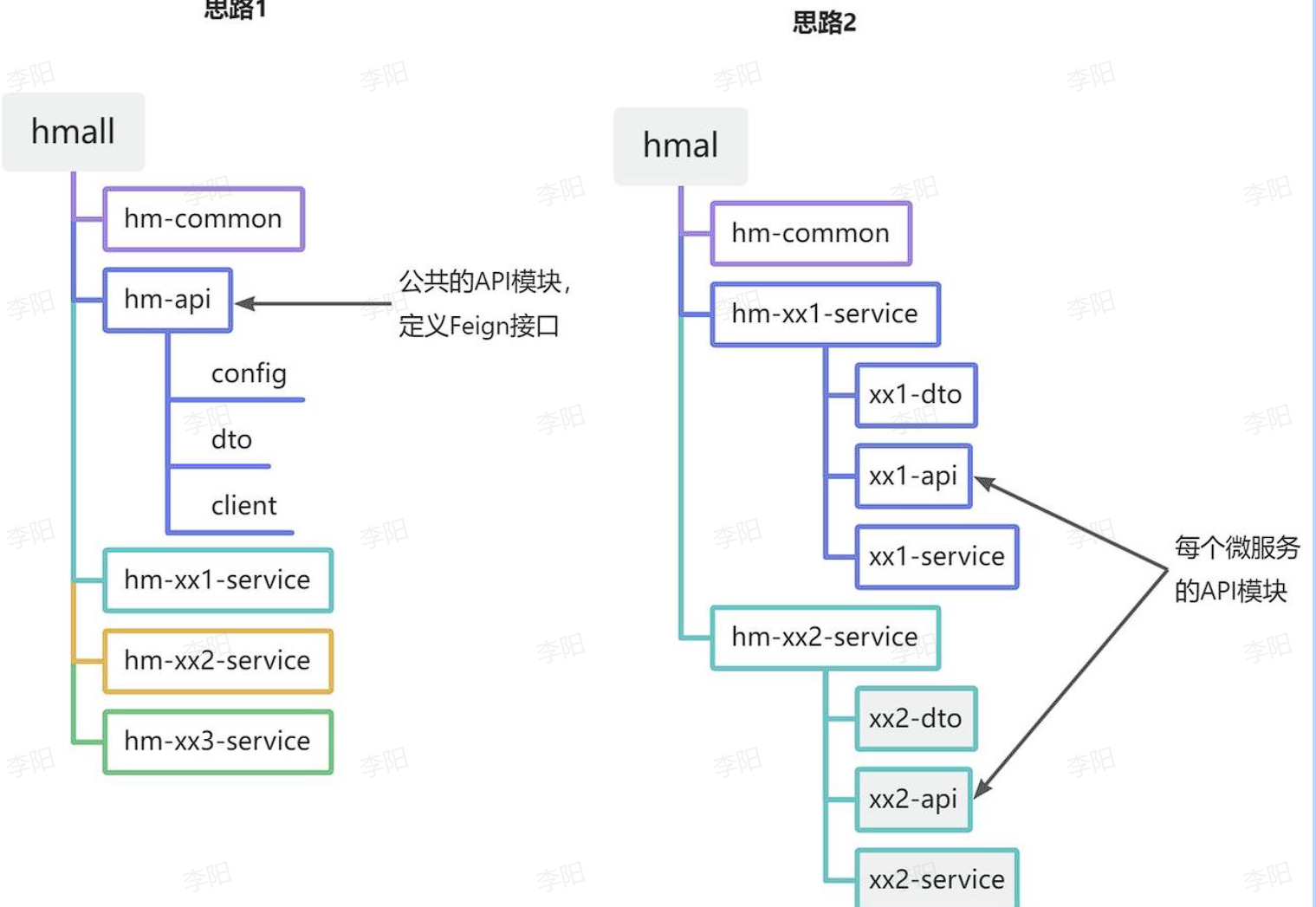
方案1抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
@SpringBootApplication这个注解中包含了@ComponentScan, 这个注解会扫描当前包(com.hmall.cart)中的文件, 而ItemClient由于被抽离到hm-api模块包下(com.hmall.api), 两者包的位置不同, 所以springboot扫描不到. 那么解决方法有: 1. 扩大扫描包的范围, 那么在启动类上添加“@ComponentScan({“com.hmall.cart”,“com.hmall.api”})“, 但此方法不推荐. 2. 使用”@import“注解, “@EnableFeignClients“就包含了@import注解, 由第三方依赖提供的 @EnableXxxxx注解, basePackages选项可以简化我们的操作, 不需要自己使用@Import.
4.6 日志输出
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认我们看不到请求日志。一般也不开启feign的日志配置,只有在需要调试feign的时候才开启日志,因为日志输出的内容有很多,输出时会影响性能。
定义日志级别
在hm-api模块下新建一个配置类,定义Feign的日志级别:
接下来,要让日志级别生效,还需要配置这个类。有两种方式:
- 局部生效:在某个
FeignClient中配置,只对当前FeignClient生效
- 全局生效:在
@EnableFeignClients中配置,针对所有FeignClient生效。
三、 微服务02
由于每个微服务都有不同的地址或端口,入口不同,相信大家在与前端联调的时候发现了一些问题:
- 请求不同数据时要访问不同的入口,需要维护多个入口地址,麻烦
- 前端无法调用nacos,无法实时更新服务列表
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,这就存在一些问题:
- 每个微服务都需要编写登录校验、用户信息获取的功能吗?
- 当微服务之间调用时,该如何传递用户信息?
不要着急,这些问题都可以在今天的学习中找到答案,我们会通过网关技术解决上述问题。今天的内容会分为3章:
- 第一章:网关路由,解决前端请求入口的问题。
- 第二章:网关鉴权,解决统一登录校验和用户信息获取的问题。
- 第三章:统一配置管理,解决微服务的配置文件重复和配置热更新问题。
通过今天的学习你将掌握下列能力:
- 会利用微服务网关做请求路由
- 会利用微服务网关做登录身份校验
- 会利用Nacos实现统一配置管理
- 会利用Nacos实现配置热更新
1. 网关路由
网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。
更通俗的来讲,网关就像是以前园区传达室的大爷。
- 外面的人要想进入园区,必须经过大爷的认可,如果你是不怀好意的人,肯定被直接拦截。
- 外面的人要传话或送信,要找大爷。大爷帮你带给目标人。
现在,微服务网关就起到同样的作用。前端请求不能直接访问微服务,而是要请求网关:
- 网关可以做安全控制,也就是登录身份校验,校验通过才放行
- 通过认证后,网关再根据请求判断应该访问哪个微服务,将请求转发过去
Route(路由): 网关的基本构件。它由一个ID、一个目的地URI、一个断言(Predicate)集合和一个过滤器(Filter)集合定义。如果断言为真,则路由被匹配。
网关也相当于一个微服务,其会注册到nacos,并拉取所有的服务信息,所以要获取某个微服务对网关来说不是难事
迷迷糊糊说这么多还是不知道网关是什么🥲🥲
- 前端发送的请求先发给网关,网关进行校验完毕之后使用负载均衡请求到具体的微服务中
- 前端只要知道网关地址即可(8080),前端所有请求地址都为8080那么就会到达网关,然后网关会根据前端的请求来去判断应该由哪个微服务来处理(判断过程就是请求的路由 ),然后网关就会帮你的请求转发到具体的微服务(路由转发)
- 网关可以利用注册中心(所有的微服务接口都存放在了注册中心),拉取所有的服务中心
- 网关来负责身份校验,这样转发就不用在此校验了
1.1 网关快速入门
网关也相当于一个微服务,其会注册到nacos,并拉取所有的服务信息,所以要获取某个微服务对网关来说不是难事。
接下来,在hm-gateway模块的resources目录新建一个application.yaml文件,内容如下:
server: |
1.2 路由属性
网关路由对应的Java类型是RouteDefinition,其中常见的属性有
- id:路由唯一标示
- uri:路由目标地址
- predicates:路由断言,判断请求是否符合当前路由。
- filters:路由过滤器,对请求或响应做特殊处理。
路由断言
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=.somehost.org,.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| weight | 权重处理 |
路由过滤器
| 名称 | 说明 | 示例 |
|---|---|---|
| AddRequestHeader | 给当前请求添加一个请求头 | AddrequestHeader=headerName, headerValue |
| RemoveRequestHeader | 移除请求中的一个请求头 | RemoveRequestHeader=headerName |
| AddResponseHeader | 给响应结果中添加一个响应头 | AddResponseHeader=headerName , headerValue |
| RemoveResponseHeader | 从响应结果中移除有一个响应头 | RemoveResponseHeader=headerName |
| RewritePath | 请求路径重写 | RewritePath=/red/ ? ( ?<segment>.*),/$\l{segment] |
| StripPrefix | 去除请求路径中的N段前缀 | StripPrefix=1,则路径/a/b转发时只保留/b |
2. 网关登录
单体架构时我们只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,不再共享数据。也就意味着每个微服务都需要做登录校验,这显然不可取。
我们的登录是基于JWT来实现的,校验JWT的算法复杂,而且需要用到秘钥。如果每个微服务都去做登录校验,这就存在着两大问题:
- 每个微服务都需要知道JWT的秘钥,不安全
- 每个微服务重复编写登录校验代码、权限校验代码,麻烦
既然网关是所有微服务的入口,一切请求都需要先经过网关。我们完全可以把登录校验的工作放到网关去做,这样之前说的问题就解决了:
- 只需要在网关和用户服务保存秘钥
- 只需要在网关开发登录校验功能
此时,登录校验的流程如图:

不过,这里存在几个问题:
- 网关路由是配置的,请求转发是Gateway内部代码,我们如何在转发之前做登录校验?
- 网关校验JWT之后,如何将用户信息传递给微服务?
- 微服务之间也会相互调用,这种调用不经过网关,又该如何传递用户信息?
2.1 网关过滤器
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
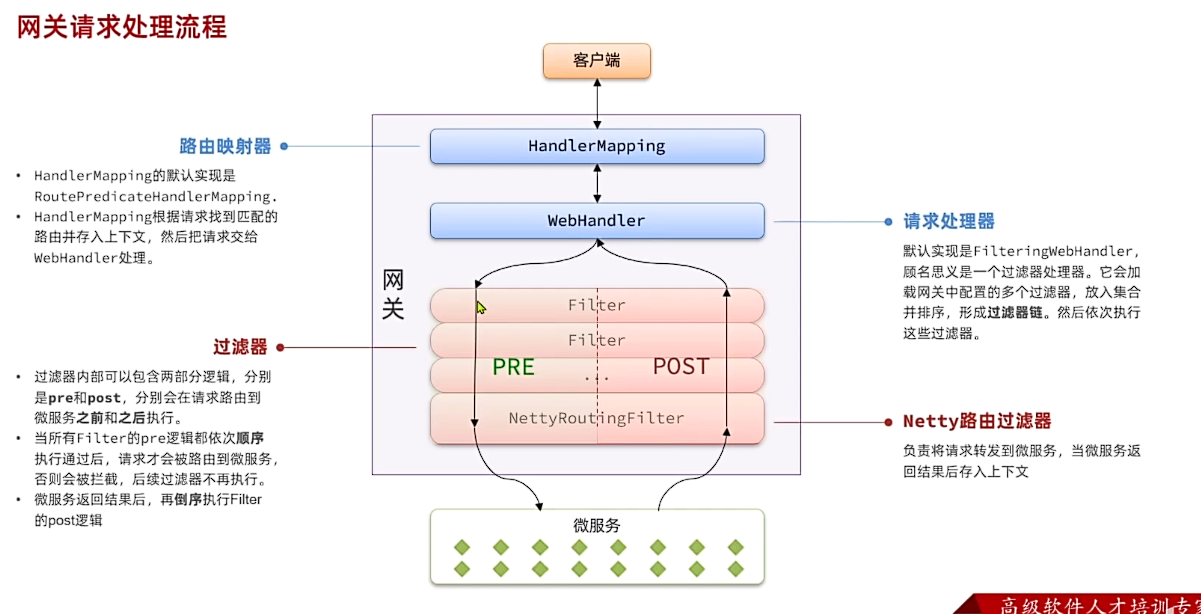
- 网关内部是没有业务逻辑的,他的任务是基于我们配的路由规则然后判断一下前端请求,到底该由哪个微服务处理,然后将请求转发到对应的微服务
- 而进行路由判断的功能就是由一个叫
handlerMapping的接口来处理的HandlerMapping的默认实现是RoutePredicateHandlerMapping(路由断言).HandlerMapping根据请求找到匹配的路由并存入上下文,然后把请求交给webHandler处理。 WebHandler默认实现是FilteringwebHandler,顾名思义是一个过滤器处理器。它会加载网关中配置的多个过滤器,放入集合并排序,形成过滤器链。然后依次执行这些过滤器。- 而整个过滤链的最后要执行
NettyRoutingFilter,负责将请求转发到微服务,当微服务返回结果后存入上下文 - 接着依次传递给其他过滤器,最终返回给用户
- 过滤器内部可以包含两部分逻辑,分别是pre和post,分别会在请求路由到微服务之前和之后执行。
- 当所有Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务,否则会被拦截,后续过滤器不再执行。微服务返回结果后,再倒序执行Filter的post逻辑
- 如果我们能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器执行顺序定义到
NettyRoutingFilter之前,这就符合我们的需求了! - 可以将用户信息保存在请求头中,然后传递给微服务,然后微服务在从请求头中取出用户信息
2.2 自定义过滤器
网关过滤器链中的过滤器有两种:
GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route. (配置的过滤器,有33种,默认不生效,配置到哪一个路由下之后就对配置的路由生效。配置到default-filter:之后就会对所有路由生效(这样就不必在所有的路由中配置类,但是所属类别依旧是GatewayFilter)。)GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。
2.3 实现登录校验
|
对于AntPathMatcher,虽然它是Spring框架的一部分,但它并不是由Spring管理的Bean。AntPathMatcher是一个工具类,用于匹配Ant风格的路径模式,它没有定义为Spring的Bean,因此Spring容器不知道如何自动注入它。
为什么需要手动创建AntPathMatcher实例?
工具类:AntPathMatcher是一个工具类,通常不需要Spring管理其生命周期。工具类是无状态的,可以在任何地方实例化和使用。
非单例:由于AntPathMatcher是无状态的,它不需要作为单例Bean管理。每次使用时创建一个新的实例是安全的,不会导致资源浪费或状态不一致的问题。
简单性:手动创建AntPathMatcher实例非常简单,只需要使用new关键字即可。这种方式代码清晰,易于理解
2.4 网关传递用户
现在,网关已经可以完成登录校验并获取登录用户身份信息。但是当网关将请求转发到微服务时,微服务又该如何获取用户身份呢?
由于网关发送请求到微服务依然采用的是Http请求,因此我们可以将用户信息以请求头的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此我们可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
据图流程图如下:
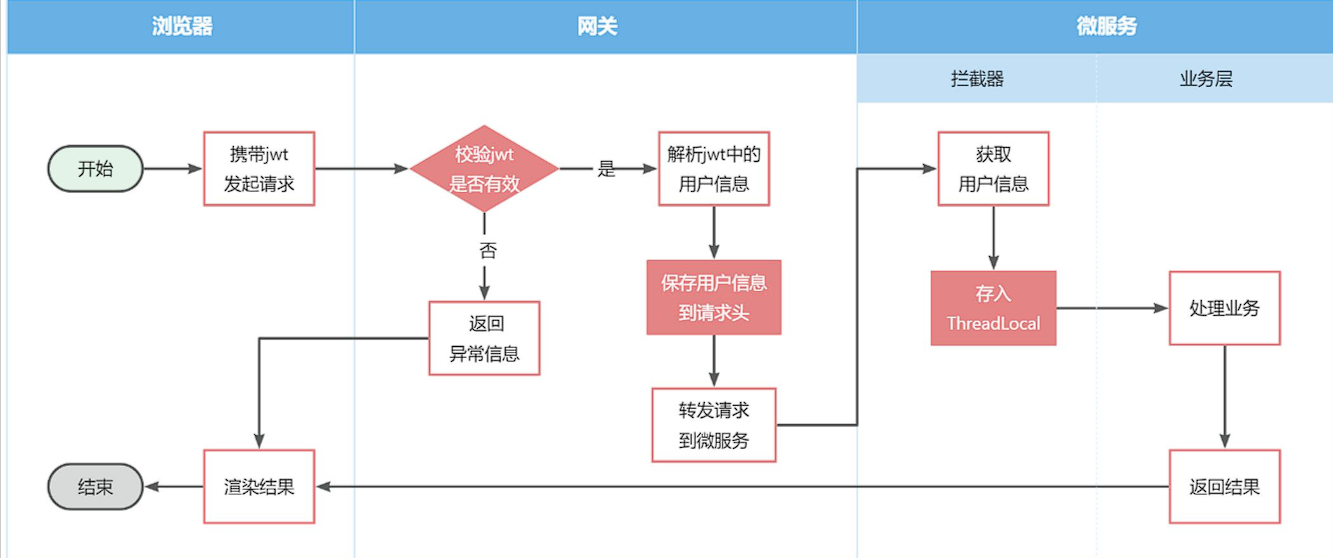
因此,接下来我们要做的事情有:
- 改造网关过滤器,在获取用户信息后保存到请求头,转发到下游微服务
- 编写微服务拦截器,拦截请求获取用户信息,保存到
ThreadLocal后放行
保存用户到请求头
首先,我们修改登录校验拦截器的处理逻辑,保存用户信息到请求头中:

修改AuthGlobalFilter
// 5.如果有效,传递用户信息 |
- 拦截器先通过 Token 解析出
userId,再将其放入请求头; - 后续的 Controller 可以直接从请求头
user-Info中获取userId,无需再次解析 Token,提高效率。
拦截器获取用户
需求:由于每个微服务都可能有获取登录用户的需求,因此我们直接在hm-common模块定义拦截器,这样微服务只需要引入依赖即可生效,无需重复编写。
package com.hmall.common.interceptors; |
这里只是写了一个拦截器类,但是并没有注册到springmvc拦截器里。要想注册进去需要进行配置:编写config配置类WebMvcConfigurer ,将其add进去
当请求从 Spring Cloud Gateway(WebFlux、Netty驱动)进入下游 Spring MVC 微服务时,exchange 不会被直接传递,而是 自动被底层 HTTP 协议转换为标准的 HttpServletRequest 和 HttpServletResponse。
spring-web通过线程池复用线程,并且不是每次使用user-service都会覆盖user信息,所以有必要在一次请求完成后清理user信息
拦截器生命周期:
preHandle() → 2. Controller & Service等 → 3. postHandle()(如有) → 4. afterCompletion()
特殊情况处理如果请求在 preHandle 返回 false(拦截请求):不会执行 Controller,但 仍会触发 afterCompletion(Spring 5.3+ 行为)。
配置拦截器
springMVC拦截器需要配置@configuration,进行配置才能生效
|
- 通过 registry.addInterceptor(new UserInfoInterceptor()) 将一个名为 UserInfoInterceptor 的拦截器添加到拦截器注册表中。这样自定义的拦截器才会生效
- 添加@ConditionalOnClass(DispatcherServlet.class)的原因:因为hm-gateway中也引用了common模块,而我们知道gateway使用的openfeign虽然也处理http请求,但是底层不是靠SpringMvc实现的,而现在设计了只要引用common这个包就会自动装配MvcConfig配置类,然而hm-gateway底层没有springmvc自然无法自动装配MvcConfig配置类,会报错。所以我们需要设计成只有依赖了SpringMvc的微服务模块才自动装配,而SpringMvc的核心类就是DispatcherServlet.class,所以只有有DispatcherServlet.class这个类的微服务模块才会自动装配MvcConfig配置类
- @ConditionalOnClass 是 Spring Boot 中的一个条件注解,它用于在特定类存在于类路径上时才启用配置。因此特定的类就是DispatcherServlet.class只要再pom.xml中加入spring-boot-starter-web就会存在DispatcherServlet类
- DispatcherServlet.class 是 Spring MVC 的核心组件之一,通常用于处理 HTTP 请求。如果存在 DispatcherServlet,说明当前项目中使用了 Spring MVC,Spring 会加载 MvcConfig 配置类
- 除了hm-gateway外底层都是springMVC,那要想不让网关得到这个WebMvcconfigurer配置,那就要;利用SpringMVC的特点去排除它,SprngMVC都有一个DispatcherServlet的api。
- 当我们配置了扫描时,其他的微服务就会使用这个拦截器配置的内容,但是网关也使用了这个配置类,网关没有MVC的内容因此会报错。
添加扫描
spring.factories
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ |
- 不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是
com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。基于SpringBoot的自动装配原理,我们要将其添加到resources目录下的META-INF/spring.factories文件中: - 依赖虽然被引入,但@ComponentScan默认扫描启动类所在的包及其子包,这里没在对应的扫描范围内所有没有注册。可以@ComponentScan添加包范围;在对应模块通过spring.factories文件将对应配置类的全限定名写进去,利用Springboot自动配置原理,其他微服务引入对应模块依赖,在启动后会进行Bean注册;同样也还可以用@Import导入对应的Bean组件或配置类
- spring.factories可以基于springboot的自动装配机制自动发现并装配配置类。简单来说,就是所有微服务都无法扫描到这个拦截器,我们可以给每一个微服务的启动类Application加上compinentscan指定扫描这个拦截器,但是,微服务数量庞大,显然不是个好办法,利用SpringBoot的自动装配原理就简单的多
结果
这样我们请求单个购物车就查询不到用户信息了

: ==> Preparing: SELECT id,user_id,item_id,num,name,spec,price,image,create_time,update_time FROM cart WHERE (user_id = ?) |
1.3.5 OpenFeign传递用户
请求从网关到交易时会被mvc拦截,将userinfo存入threadlocal,当这个请求执行完之后,afterCompletion会清除threadlocal,故当交易发请求到商品时是没有ui的
前端发起的请求都会经过网关再到微服务,由于我们之前编写的过滤器和拦截器功能,微服务可以轻松获取登录用户信息。
但有些业务是比较复杂的,请求到达微服务后还需要调用其它多个微服务。比如下单业务,流程如下:
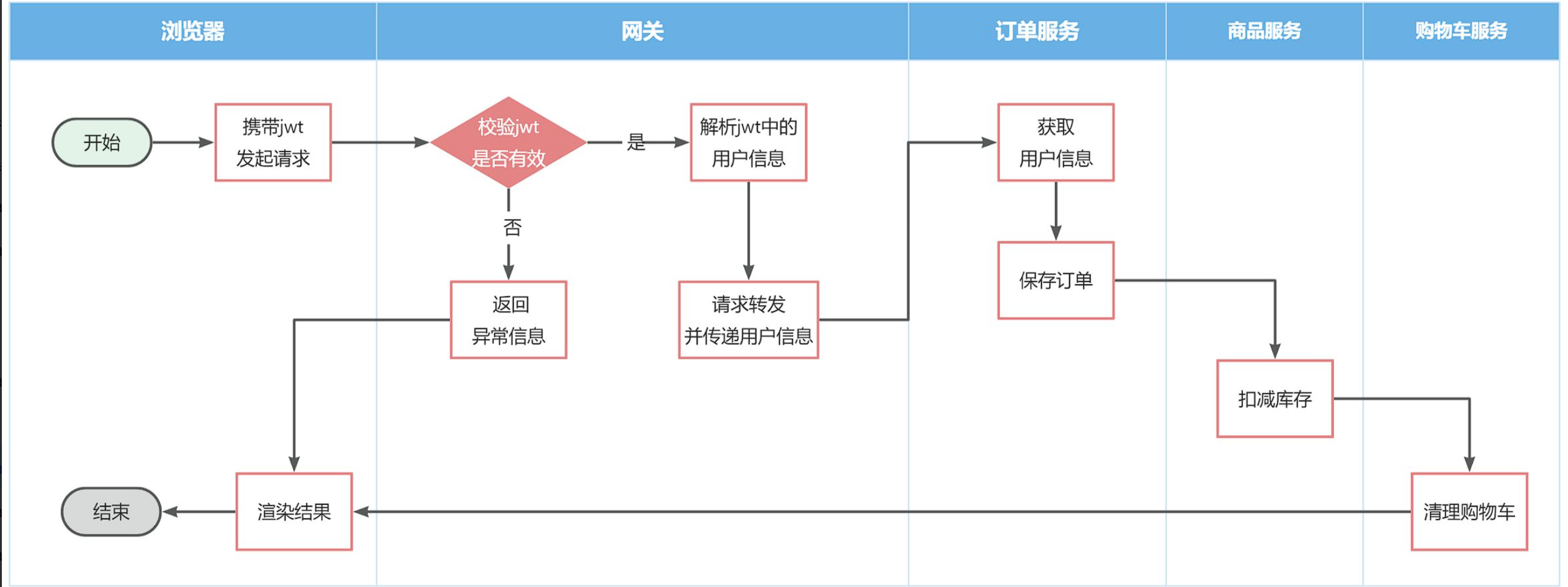
下单的过程中,需要调用商品服务扣减库存,调用购物车服务清理用户购物车。而清理购物车时必须知道当前登录的用户身份。但是,订单服务调用购物车时并没有传递用户信息,购物车服务无法知道当前用户是谁!
由于微服务获取用户信息是通过拦截器在请求头中读取,因此要想实现微服务之间的用户信息传递,就必须在微服务发起调用时把用户信息存入请求头。
ThreadLocal:仅限单JVM线程内,用于存储线程级别的上下文(如用户身份、事务ID)。其生命周期与线程绑定,无法跨进程或跨服务传递。
微服务间通信:本质是跨进程的分布式调用,服务可能部署在不同物理节点。ThreadLocal无法穿透网络边界,无法在服务A的线程中直接访问服务B的线程数据。
服务调用,即跨进程的服务调用,而ThreadLocal只仅限于当前服务内部的范围,所以无法使用,但网关那里刚开始不是已经通过过滤器进行了userInfo存入请求头中吗?为什么后续微服务a调用服务b时,需要再次将userInfo存入请求头才能传递用户信息呢?那是因为——>HTTP协议无状态:每个请求默认不携带上一个请求的上下文(直接理解成,每次发送的都是一个新的http请求,所以需要我们自己给该请求做标识)。 最后记住:拦截器+Feign组合:是实现微服务间身份透传的标准模式。
拦截器是属于微服务的,过滤器是属于网关的;拦截器从请求头获取userId,并保存在context中,过滤器解析jwt并保存在请求头中;
微服务之间调用是基于OpenFeign来实现的,并不是我们自己发送的请求。我们如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor

不放在common中,因为不是所有模块都需要,例如网关微服务就不需要FeignClient 其实就是拦截下来OpenFeign的转发请求,然后再请求头中添加上user-info字段后放行。
DefaultFeignConfig
public class DefaultFeignConfig { |
3. 配置管理
到目前为止我们已经解决了微服务相关的几个问题:
- 微服务远程调用
- 微服务注册、发现
- 微服务请求路由、负载均衡
- 微服务登录用户信息传递
不过,现在依然还有几个问题需要解决:
- 网关路由在配置文件中写死了,如果变更必须重启微服务
- 某些业务配置在配置文件中写死了,每次修改都要重启服务
- 每个微服务都有很多重复的配置,维护成本高
这些问题都可以通过统一的配置管理器服务解决。而Nacos不仅仅具备注册中心功能,也具备配置管理的功能:
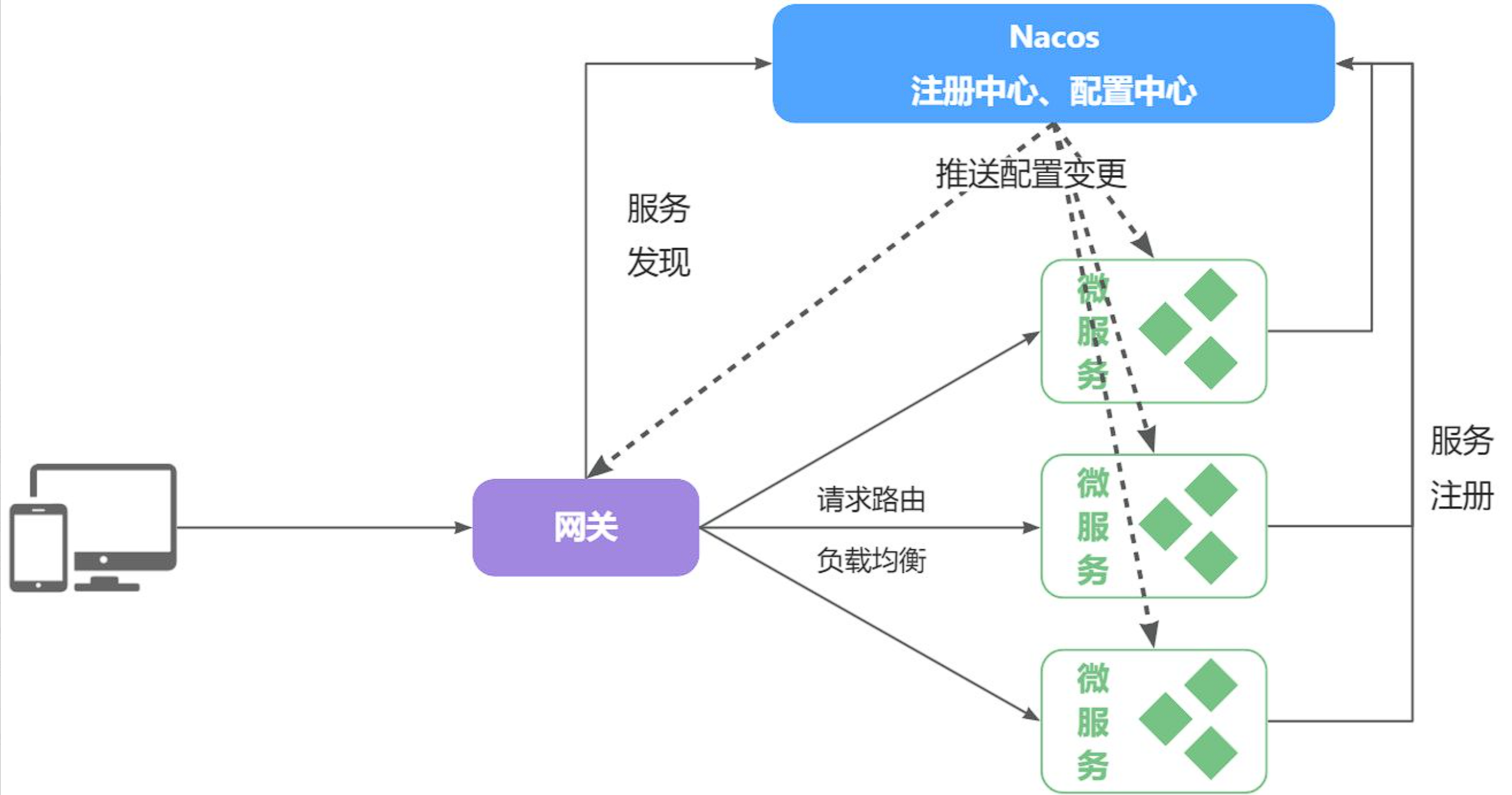
微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。
网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
3.1 配置共享
我们可以把微服务共享的配置抽取到Nacos中统一管理,这样就不需要每个微服务都重复配置了。分为两步:
- 在Nacos中添加共享配置
- 微服务拉取配置
3.1.1 添加共享配置
以cart-service为例,我们看看有哪些配置是重复的,可以抽取的:
首先是jdbc相关配置:
然后是日志配置:
然后是swagger以及OpenFeign的配置:
我们在nacos控制台分别添加这些配置。
首先是jdbc相关配置,在配置管理->配置列表中点击+新建一个配置:
在弹出的表单中填写信息:
其中详细的配置如下:
spring: |
注意这里的jdbc的相关参数并没有写死,例如:
数据库ip:通过${hm.db.host:192.168.150.101}配置了默认值为192.168.150.101,同时允许通过${hm.db.host}来覆盖默认值数据库端口:通过${hm.db.port:3306}配置了默认值为3306,同时允许通过${hm.db.port}来覆盖默认值数据库database:可以通过${hm.db.database}来设定,无默认值
然后是统一的日志配置,命名为shared-log.``yaml,配置内容如下:
logging: |
然后是统一的swagger配置,命名为shared-swagger.yaml,配置内容如下:
knife4j: |
注意,这里的swagger相关配置我们没有写死,例如:
title:接口文档标题,我们用了${hm.swagger.title}来代替,将来可以有用户手动指定email:联系人邮箱,我们用了${hm.swagger.email:``[email protected]``},默认值是[email protected],同时允许用户利用${hm.swagger.email}来覆盖。
3.2 拉取nacos
接下来,我们要在微服务拉取共享配置。将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果我们将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
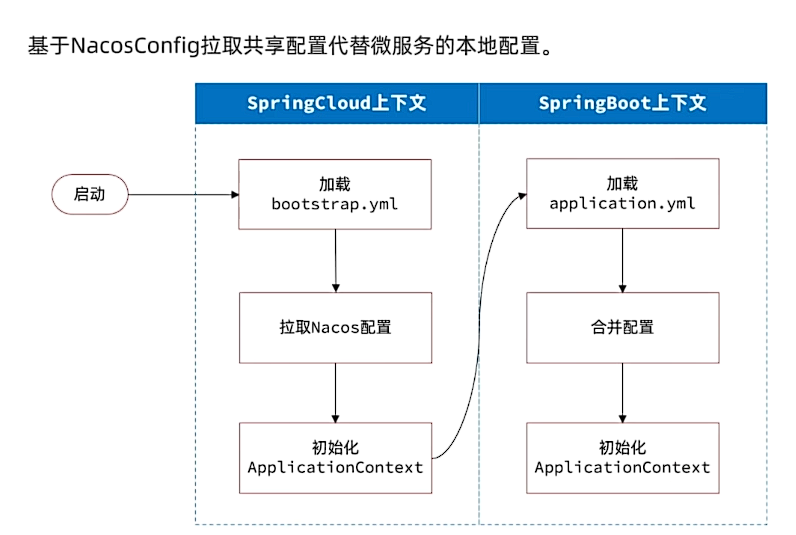
因此,微服务整合Nacos配置管理的步骤如下:
1)引入依赖:
在cart-service模块引入依赖:
<!--nacos配置管理--> |
2)新建bootstrap.yaml
在cart-service中的resources目录新建一个bootstrap.yaml文件:
内容如下:
spring: |
3)修改application.yaml
由于一些配置挪到了bootstrap.yaml,因此application.yaml需要修改为:
server: |
重启服务,发现所有配置都生效了。
3.3 配置热更新
有很多的业务相关参数,将来可能会根据实际情况临时调整。例如购物车业务,购物车数量有一个上限,默认是10,对应代码如下:
现在这里购物车是写死的固定值,我们应该将其配置在配置文件中,方便后期修改。
但现在的问题是,即便写在配置文件中,修改了配置还是需要重新打包、重启服务才能生效。能不能不用重启,直接生效呢?
这就要用到Nacos的配置热更新能力了,分为两步:
- 在Nacos中添加配置
- 在微服务读取配置

文件名称由三部分组成:
服务名:我们是购物车服务,所以是cart-servicespring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置后缀名:例如yaml
这里我们直接使用cart-service.yaml这个名称,则不管是dev还是local环境都可以共享该配置。
配置内容如下:
hm: |
接着,我们在微服务中读取配置,实现配置热更新。
在cart-service中新建一个属性读取类:
代码如下:
package com.hmall.cart.config; |
接着,在业务中使用该属性加载类:
测试,向购物车中添加多个商品:
我们在nacos控制台,将购物车上限配置为5:
无需重启,再次测试购物车功能:
加入成功!
无需重启服务,配置热更新就生效了!
3.4 动态路由
网关的路由配置全部是在项目启动时由org.springframework.cloud.gateway.route.CompositeRouteDefinitionLocator在项目启动的时候加载,并且一经加载就会缓存到内存中的路由表内(一个Map),不会改变。也不会监听路由变更,所以,我们无法利用上节课学习的配置热更新来实现路由更新。
因此,我们必须监听Nacos的配置变更,然后手动把最新的路由更新到路由表中。这里有两个难点:
- 如何监听Nacos配置变更?
- 如何把路由信息更新到路由表?

四、 微服务03
在微服务远程调用的过程中,还存在几个问题需要解决。
首先是业务健壮性问题:
例如在之前的查询购物车列表业务中,购物车服务需要查询最新的商品信息,与购物车数据做对比,提醒用户。大家设想一下,如果商品服务查询时发生故障,查询购物车列表在调用商品服 务时,是不是也会异常?从而导致购物车查询失败。但从业务角度来说,为了提升用户体验,即便是商品查询失败,购物车列表也应该正确展示出来,哪怕是不包含最新的商品信息。
还有级联失败问题:
还是查询购物车的业务,假如商品服务业务并发较高,占用过多Tomcat连接。可能会导致商品服务的所有接口响应时间增加,延迟变高,甚至是长时间阻塞直至查询失败。
此时查询购物车业务需要查询并等待商品查询结果,从而导致查询购物车列表业务的响应时间也变长,甚至也阻塞直至无法访问。而此时如果查询购物车的请求较多,可能导致购物车服务的Tomcat连接占用较多,所有接口的响应时间都会增加,整个服务性能很差, 甚至不可用。
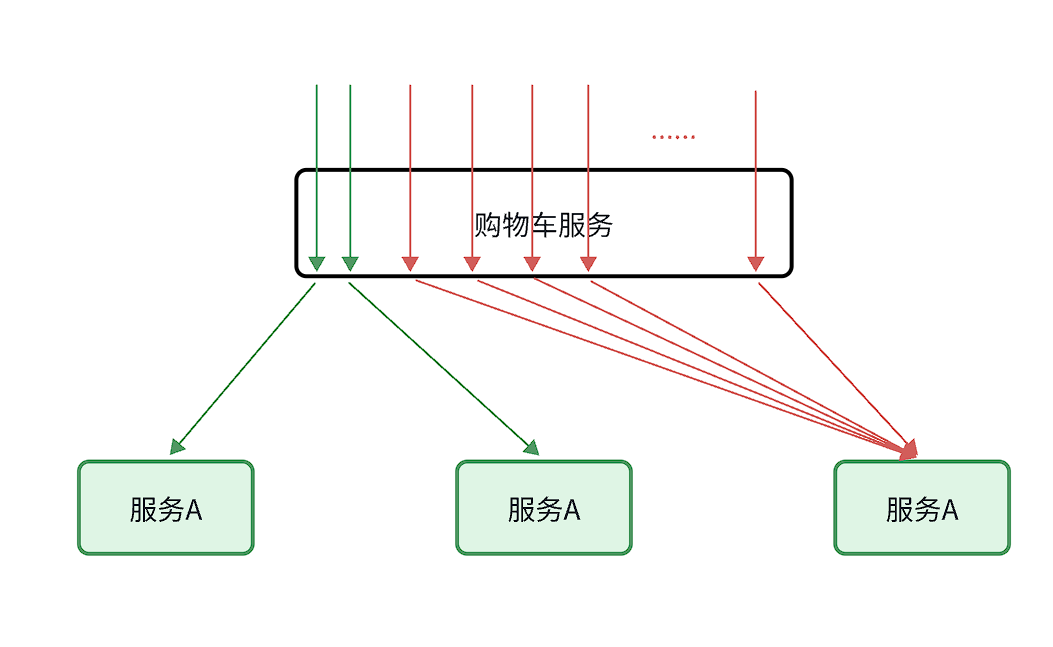
依次类推,整个微服务群中与购物车服务、商品服务等有调用关系的服务可能都会出现问题,最终导致整个集群不可用。
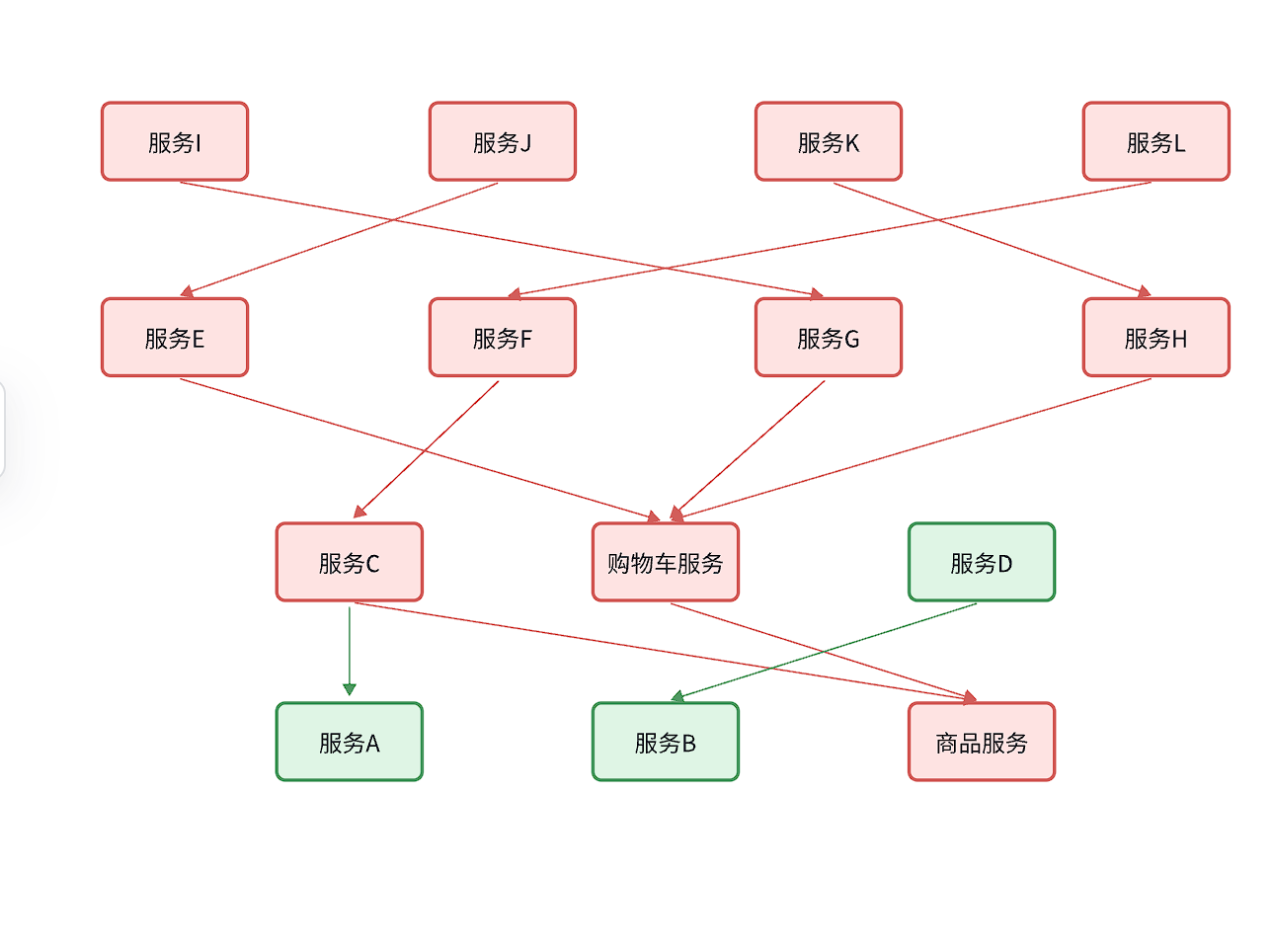
这就是级联失败问题,或者叫雪崩问题。
级联失败(Cascading Failure)是指一个系统中的局部故障引发连锁反应,导致其他部分相继失效,最终造成更大范围甚至整个系统崩溃的现象。
还有跨服务的事务问题:
比如昨天讲到过的下单业务,下单的过程中需要调用多个微服务:
- 商品服务:扣减库存
- 订单服务:保存订单
- 购物车服务:清理购物车
这些业务全部都是数据库的写操作,我们必须确保所有操作的同时成功或失败。但是这些操作在不同微服务,也就是不同的Tomcat,这样的情况如何确保事务特性呢?
4.1 雪崩问题
雪崩问题产生的原因?
- 微服务相互调用,服务提供者出现故障或阻塞。
- 服务调用者没有做好异常处理,导致自身故障。
- 调用链中的所有服务级联失败,导致整个集群故障
如何避免雪崩
尽量避免服务出现故障或阻塞。
- 保证代码的健壮性;
- 保证网络畅通;
- 能应对较高的并发请求;
服务调用者做好远程调用异常的后备方案,避免故障扩散
4.2 微服务保护
4.2.1 服务保护方案
微服务保护的方案有很多,比如:
- 请求限流
- 线程隔离
- 服务熔断
这些方案或多或少都会导致服务的体验上略有下降,比如请求限流,降低了并发上限;线程隔离,降低了可用资源数量;服务熔断,降低了服务的完整度,部分服务变的不可用或弱可用。因此这些方案都属于服务降级的方案。但通过这些方案,服务的健壮性得到了提升,
4.2.2 请求限流
服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发不是一直很高,而是突发的。因此请求限流,就是限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。
请求限流往往会有一个限流器,数量高低起伏的并发请求曲线,经过限流器就变的非常平稳。这就像是水电站的大坝,起到蓄水的作用,可以通过开关控制水流出的大小,让下游水流始终维持在一个平稳的量。

4.2.3 线程隔离
当一个业务接口响应时间长,而且并发高时,就可能耗尽服务器的线程资源,导致服务内的其它接口受到影响。所以我们必须把这种影响降低,或者缩减影响的范围。线程隔离正是解决这个问题的好办法。
线程隔离的思想来自轮船的舱壁模式:
轮船的船舱会被隔板分割为N个相互隔离的密闭舱,假如轮船触礁进水,只有损坏的部分密闭舱会进水,而其他舱由于相互隔离,并不会进水。这样就把进水控制在部分船体,避免了整个船舱进水而沉没。
为了避免某个接口故障或压力过大导致整个服务不可用,我们可以限定每个接口可以使用的资源范围,也就是将其“隔离”起来。
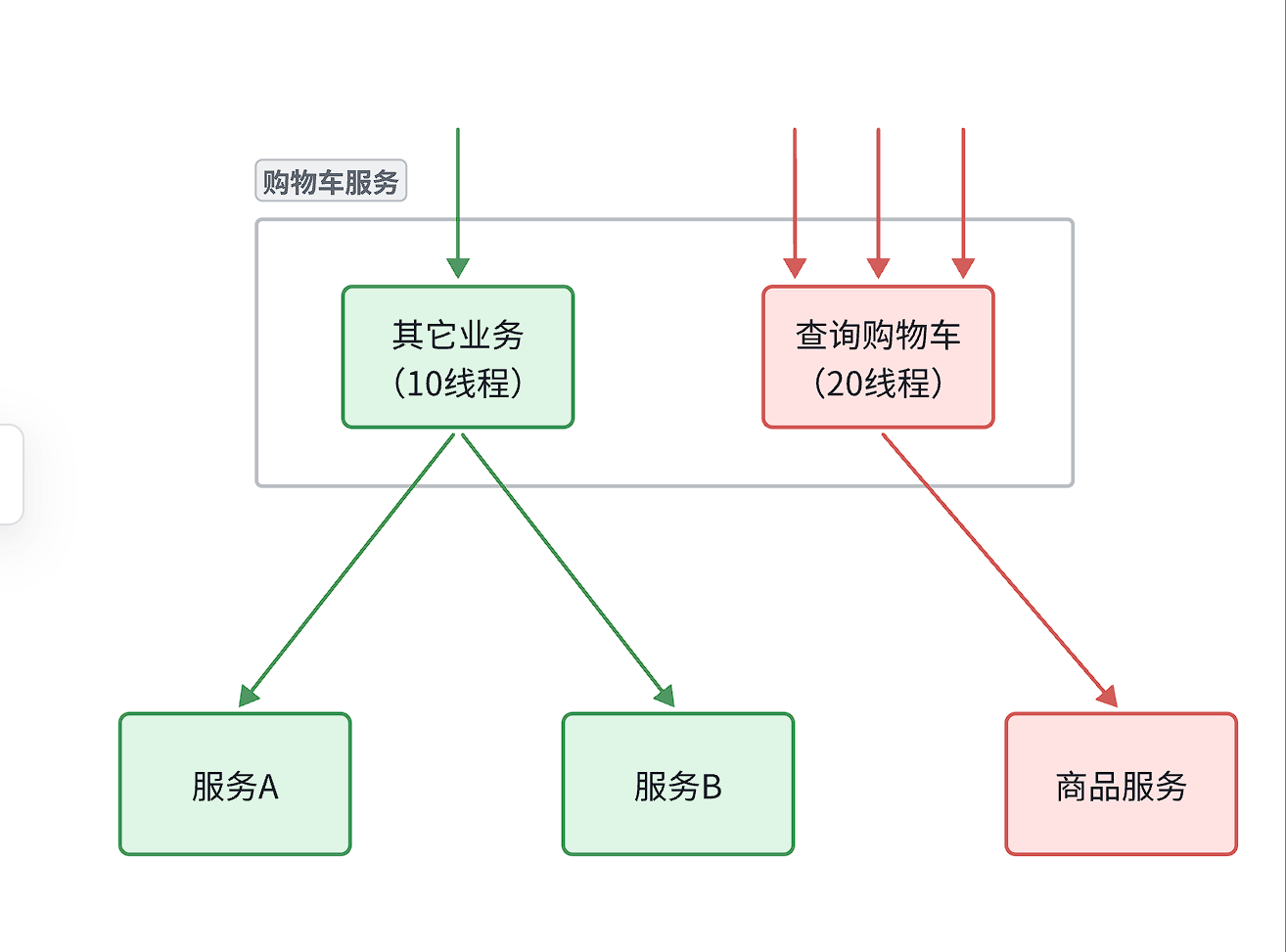
如图所示,我们给查询购物车业务限定可用线程数量上限为20,这样即便查询购物车的请求因为查询商品服务而出现故障,也不会导致服务器的线程资源被耗尽,不会影响到其它接口。
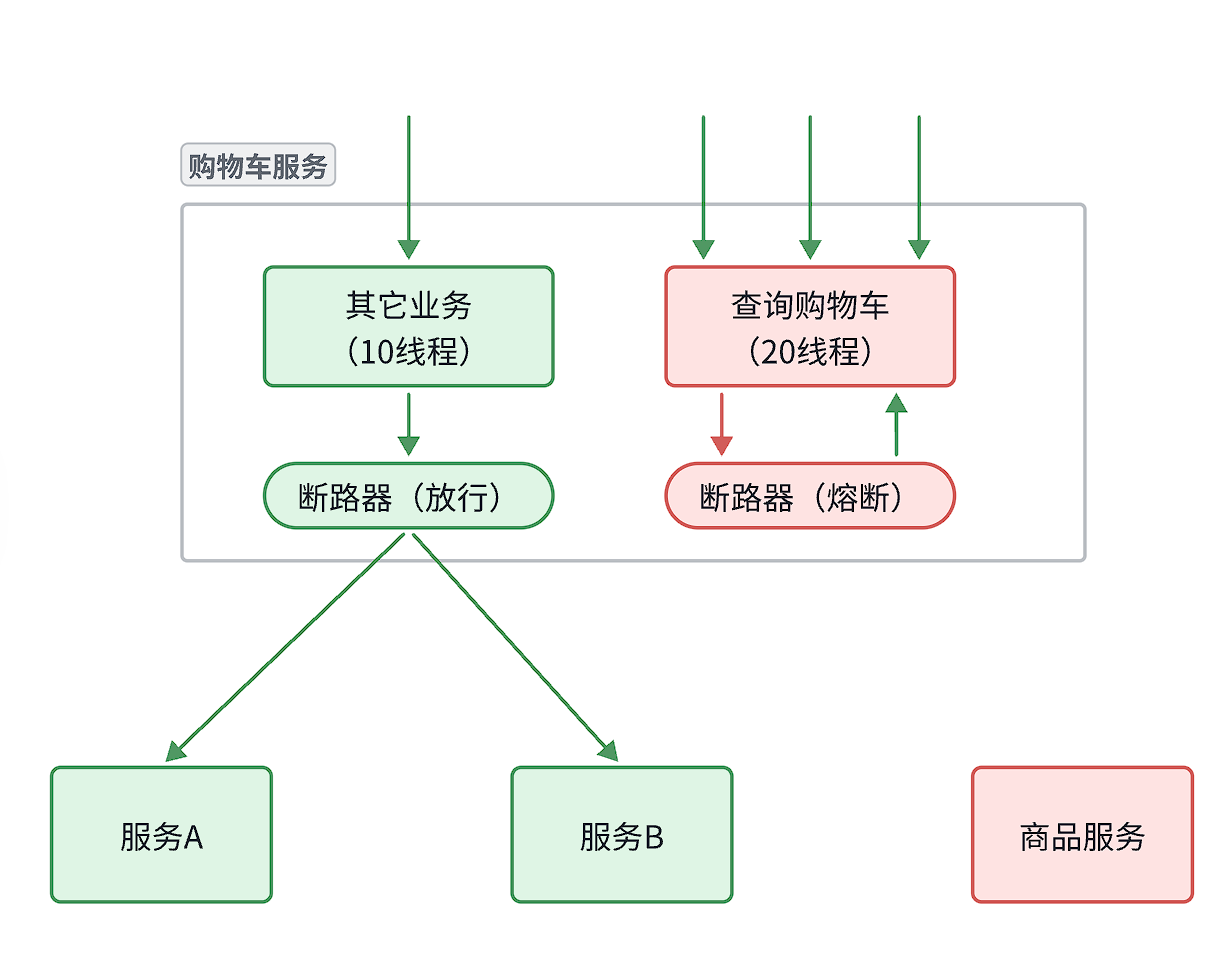
4.2.4 服务熔断
线程隔离虽然避免了雪崩问题,但故障服务(商品服务)依然会拖慢购物车服务(服务调用方)的接口响应速度。而且商品查询的故障依然会导致查询购物车功能出现故障,购物车业务也变的不可用了。
所以,我们要做两件事情:
- 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。
- 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。
这里服务提供方就是商品服务,异常比例过高意思就是说如果过往记录中发现调用10商品服务,有6次失败(60%),而熔断决策这里是当失败率超过阈值(如50%),购物车服务(调用方)的熔断器会:
- 拒绝后续请求:不再真正调用商品服务,避免资源浪费。
- 直接走降级逻辑:返回缓存数据、默认值或友好提示。
熔断恢复:
经过一段时间(如5秒),熔断器尝试放行一个请求探测商品服务是否恢复。若成功,则逐步关闭熔断。
4.3 Sentinel
微服务保护的技术有很多,但在目前国内使用较多的还是Sentinel,所以接下来我们学习Sentinel的使用。
Sentinel是阿里巴巴开源的一款服务保护框架,目前已经加入SpringCloudAlibaba中。
Sentinel 的使用可以分为两个部分:
- 核心库(Jar包):不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
- 控制台(Dashboard):Dashboard 主要负责管理推送规则、监控、管理机器信息等。
4.3.1 Sentinel安装
Window安装
下载jar包,cmd运行:
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar |
访问http://localhost:8090页面,就可以看到sentinel的控制台了
需要输入账号和密码,默认都是:sentinel
登录后,即可看到控制台,默认会监控sentinel-dashboard服务本身
Docker运行
docker run -d --name sentinel -p 8090:8858 --network hm-net bladex/sentinel-dashboard:1.8.7 |
然后运行http://192.168.163.129:8090
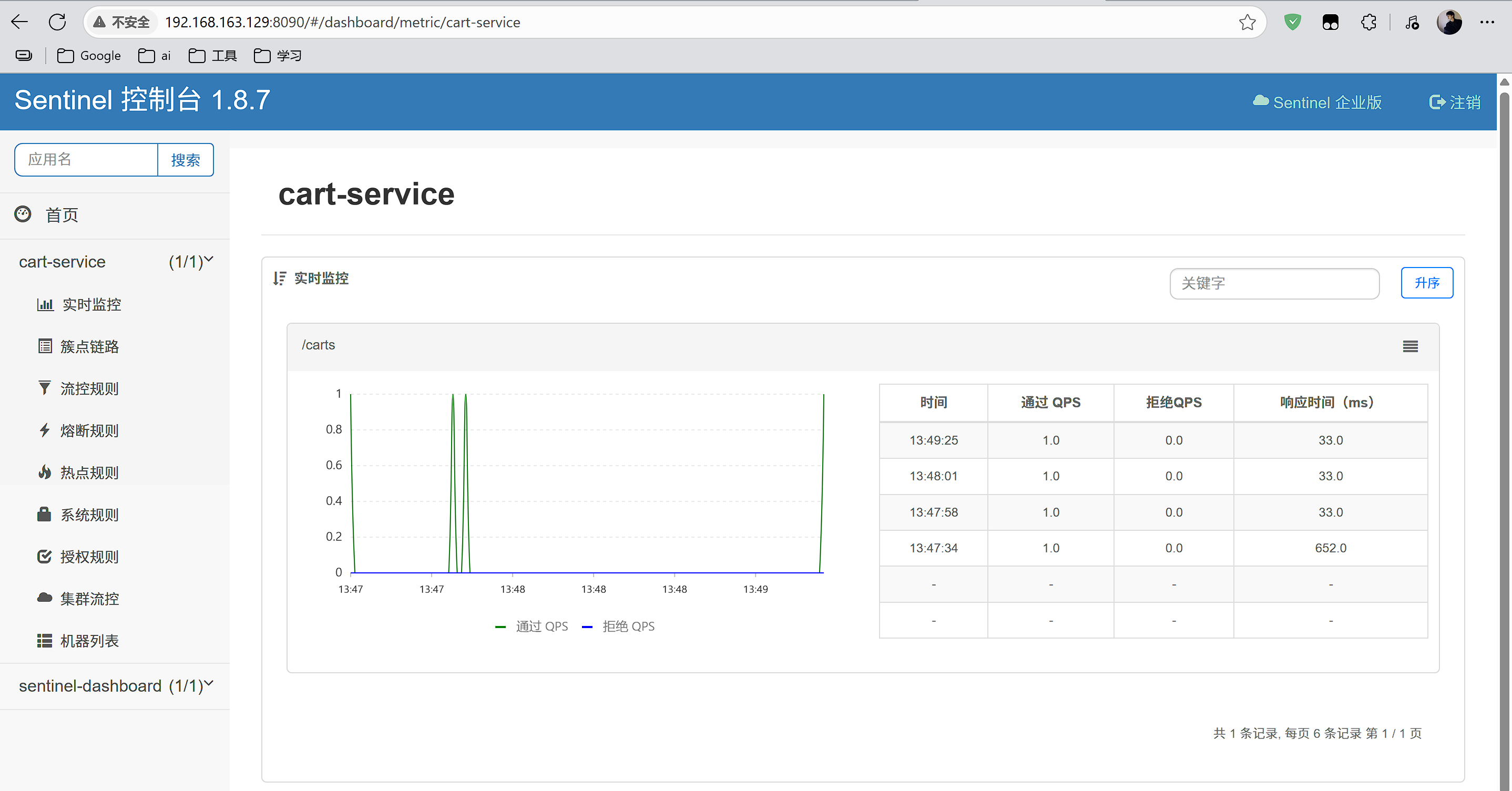
4.3.2 Fallback
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给FeignClient编写失败后的降级逻辑有两种方式:
- 方式一:FallbackClass,无法对远程调用的异常做处理
- 方式二:FallbackFactory,可以对远程调用的异常做处理,我们一般选择这种方式。
4.4 分布式事务
首先我们看看项目中的下单业务整体流程:
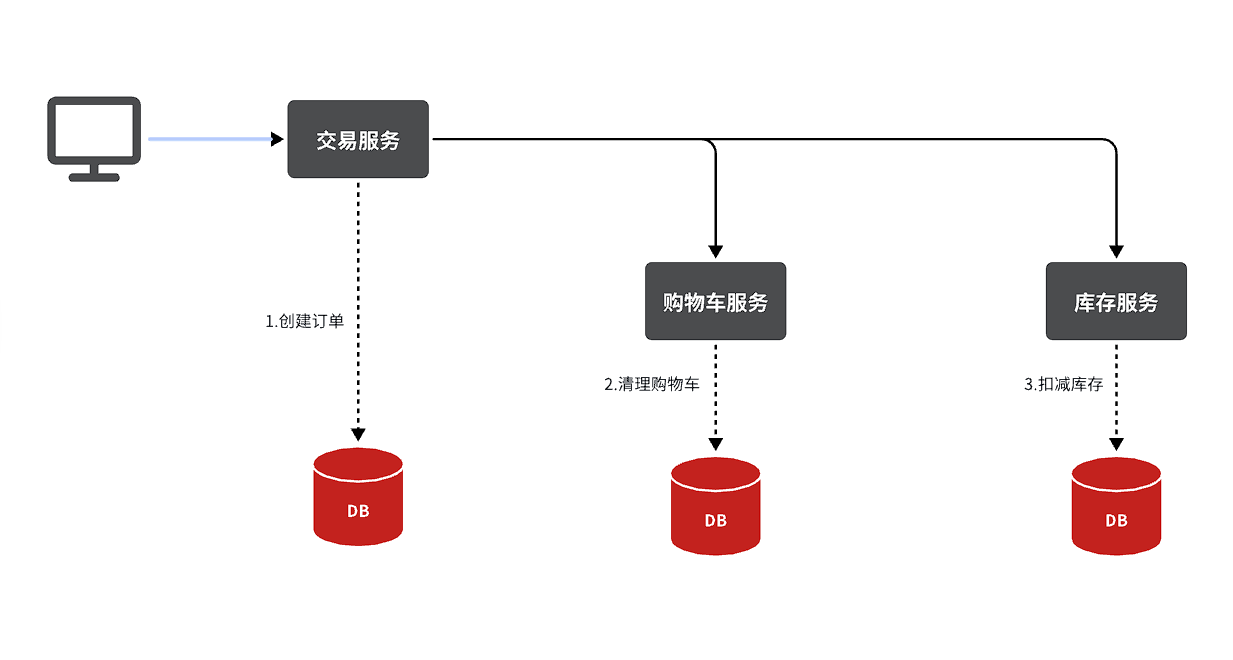
由于订单、购物车、商品分别在三个不同的微服务,而每个微服务都有自己独立的数据库,因此下单过程中就会跨多个数据库完成业务。而每个微服务都会执行自己的本地事务:
- 交易服务:下单事务
- 购物车服务:清理购物车事务
- 库存服务:扣减库存事务
整个业务中,各个本地事务是有关联的。因此每个微服务的本地事务,也可以称为分支事务。多个有关联的分支事务一起就组成了全局事务。我们必须保证整个全局事务同时成功或失败。
我们知道每一个分支事务就是传统的单体事务,都可以满足ACID特性,但全局事务跨越多个服务、多个数据库,是否还能满足呢?
我们来做一个测试,先进入购物车页面:

目前有4个购物车,然结算下单,进入订单结算页面:
然后将购物车中某个商品的库存修改为0:
然后,提交订单,最终因库存不足导致下单失败:
然后我们去查看购物车列表,发现购物车数据依然被清空了,并未回滚:
事务并未遵循ACID的原则,归其原因就是参与事务的多个子业务在不同的微服务,跨越了不同的数据库。虽然每个单独的业务都能在本地遵循ACID,但是它们互相之间没有感知,不知道有人失败了,无法保证最终结果的统一,也就无法遵循ACID的事务特性了。
这就是分布式事务问题,出现以下情况之一就可能产生分布式事务问题:
- 业务跨多个服务实现
- 业务跨多个数据源实现
接下来这一章我们就一起来研究下如何解决分布式事务问题。
4.4.1 Seata
解决分布式事务的方案有很多,但实现起来都比较复杂,因此我们一般会使用开源的框架来解决分布式事务问题。在众多的开源分布式事务框架中,功能最完善、使用最多的就是阿里巴巴在2019年开源的Seata了。
其实分布式事务产生的一个重要原因,就是参与事务的多个分支事务互相无感知,不知道彼此的执行状态。因此解决分布式事务的思想非常简单:
就是找一个统一的事务协调者,与多个分支事务通信,检测每个分支事务的执行状态,保证全局事务下的每一个分支事务同时成功或失败即可。大多数的分布式事务框架都是基于这个理论来实现的。
Seata也不例外,在Seata的事务管理中有三个重要的角色:
- TC (Transaction Coordinator) - **事务协调者:**维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - **事务管理器:**定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - **资源管理器:**管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Seata的工作架构如图所示:
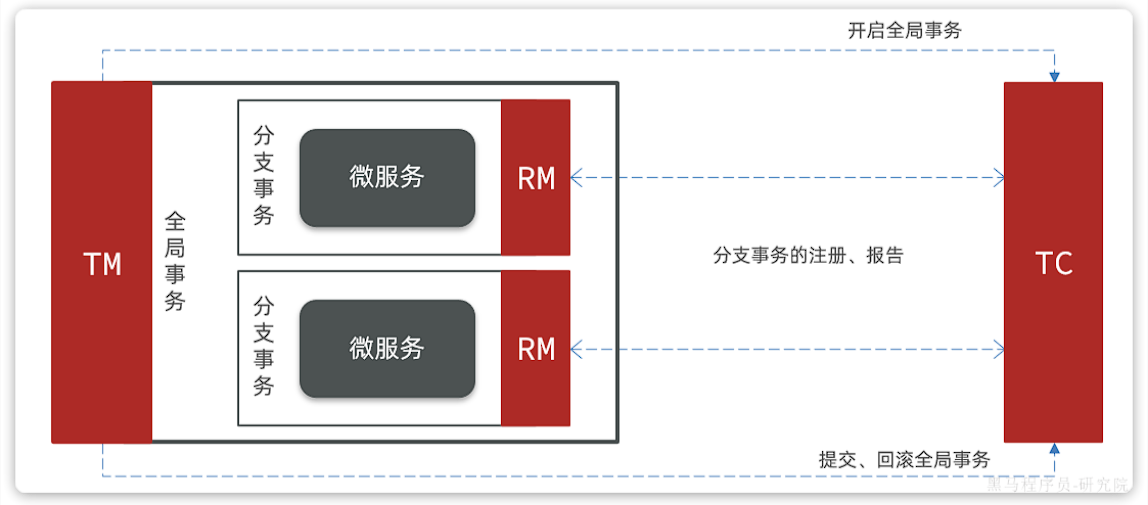
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
三者关系的小例子
可以把 Seata 处理分布式事务的过程,类比成组织一次多人协作的搬家任务,用生活化场景理解三个角色:
- TM(事务管理器):搬家发起人
- 作用:决定要不要开始 “全局事务(搬家这件事)”,以及最后成功了提交结果(搬完)、失败了回滚(不搬或恢复原样)。
- 举例:你(TM)想组织一次搬家,先拍板 “周末要把家里东西搬到新房”(定义全局事务范围),然后通知大家开始干活(开启全局事务)。要是中途发现新房没收拾好,你说 “不搬了,东西放回原处”(回滚全局事务);要是一切顺利,你确认 “搬完啦,任务结束”(提交全局事务)。
- TC(事务协调者):搬家总指挥
- 作用:盯着所有 “分支事务(打包、搬运、拆装家具等环节)” 的状态,协调大家一起成功或一起失败。
- 举例:你请了个指挥(TC),他负责盯着:打包队有没有把东西包好(分支事务状态)、搬运车有没有把东西运到(分支事务状态)、拆装队有没有把家具装好(分支事务状态)…… 要是打包队说 “包一半发现东西太多,搞不定”,指挥(TC)就通知所有人 “别搬了,各自恢复原样”;要是所有人都反馈 “搞定”,指挥(TC)就告诉大家 “可以收尾,任务完成”。
- RM(资源管理器):具体干活的小组
- 作用:管理自己负责的 “分支事务(比如打包组管打包、搬运组管运输)”,随时给 TC 汇报进度和状态。
- 举例:
- 打包组(RM1):负责把家里东西分类打包,打包完了跟指挥(TC)说 “我们包好啦”;要是打包到一半发现东西坏了,也跟指挥(TC)说 “这里搞不定,需要回退”。
- 搬运组(RM2):负责把打包好的东西运到新房,路上车坏了(分支事务失败),就跟指挥(TC)汇报 “运不了,得终止”;要是顺利运到,就说 “送达成功”。
- 拆装组(RM3):负责在新房把家具装好,装完汇报 “装好了”;装到一半发现零件少了,汇报 “装不了,得回退”。
总结流程: 你(TM)发起搬家(全局事务)→ 指挥(TC)协调打包、搬运、拆装(分支事务)→ 每个小组(RM)干活并汇报状态 → 指挥(TC)根据所有人状态,决定让大家一起成功(搬完)或一起回滚(不搬 / 恢复)→ 你(TM)最终确认结果。
4.4.2 Seata配置
docker run --name seata \ |
这样就使用Docker成功部署了
4.4.3 微服务集成Seata
导入依赖
为了方便各个微服务集成seata,我们需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖:
<!--统一配置管理--> |
配置nacos
首先在nacos上添加一个共享的seata配置,命名为shared-seata.yaml:
内容如下:
seata: |
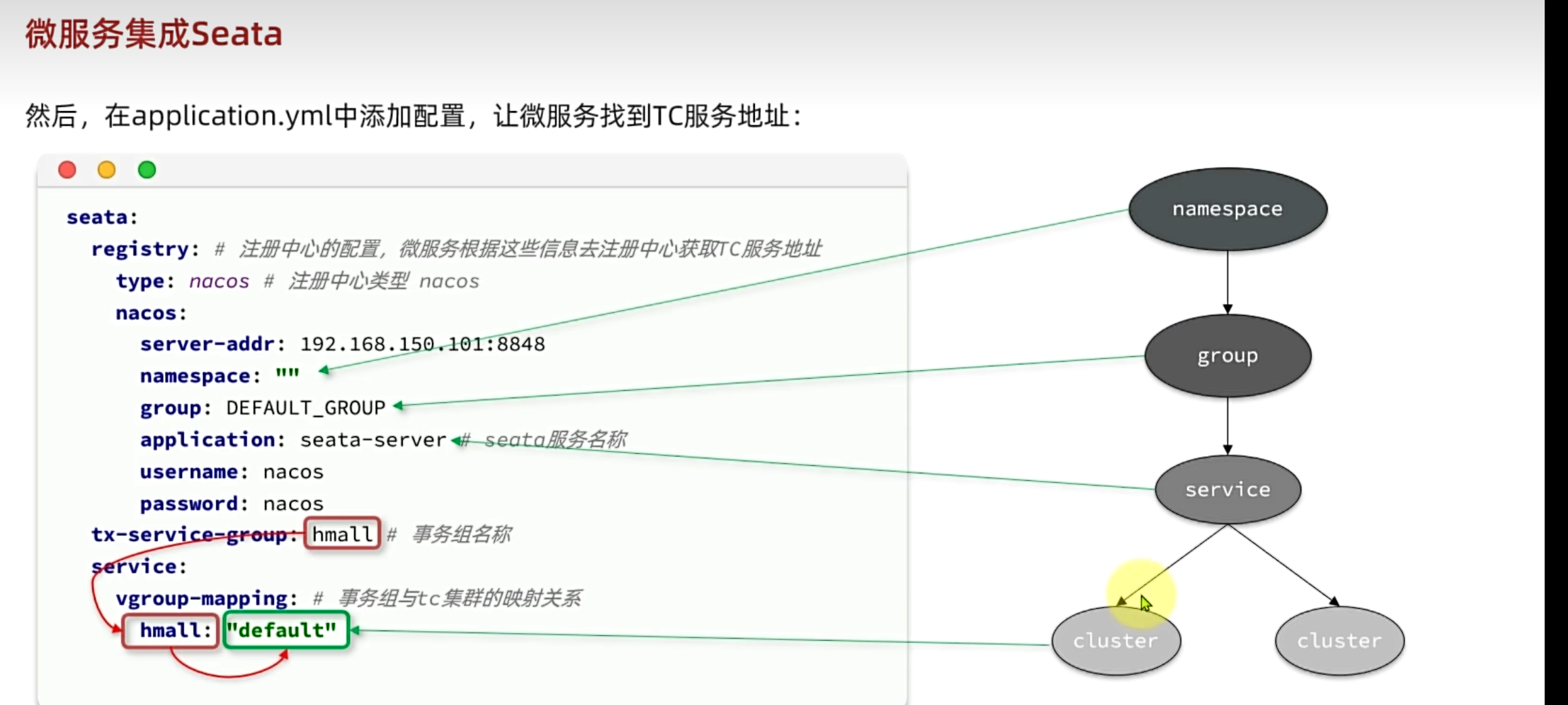
改造配置
bootstrap.yaml:
内容如下:
spring: |
4.4.4 XA模式(面试题)
XA规范是X/Open组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA规范描述了全局的TM与局部的RM之间的接口,几乎所有主流的关系型数据库都对XA规范提供了支持。Seata的XA模式如下:

一阶段的工作
- RM注册分支事务到TC
- RM执行分支业务SQL但是不提交
- RM报告执行状态到TC
二阶段的工作
- TC检测各分支事务执行状态(如果成功/失败,通知RM提交/回滚事务)
- RM接收TC指令,提交/回滚事务
具体流程
- 当方法执行时,全局事务(TM)向TC注册一个全局事务
- TM执行内部业务逻辑,调用每一个分支
- RM会拦截对SQL的操作,RM会向TC注册分支事务
- 然后再放行去执行业务的SQL(SQL执行完毕后不可以提交)
- 当所有方法执行完毕TM会向TC发送全局事务结束的信息
- TC会检查注册分支的事务状态 ,如果发现都成功了就向所有分支发送提交/回滚的指令
- 这些事务才能提交事务释放锁(反之下达回滚的命令)
优缺点
XA模式的优点是什么?
- ·事务的强一致性,满足ACID原则。
- ·常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- ·因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- ·依赖关系型数据库实现事务
回滚日志
01:18:28.936 INFO --- [rverHandlerThread_1_4_500] i.s.s.coordinator.DefaultCoordinator : Begin new global transaction applicationId: trade-serviceup: hmall, transactionName: createOrder(com.hmall.trade.domain.dto.OrderFormDTO),timeout:60000,xid:192.168.163.129:8099:45712777161203713 |
4.4.5 AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷

阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
具体流程
- 全局事务方法开启时TM会向TC注册一个全局事务
- TM调用所有的分支
- ,在操作SQL之前会被RM拦截,RM会向TC注册分支事务
- 微服务的item执行具体的SQL语句并且立刻提交事务
- item在执行SQL之前先去生成一个修改数据库之前的数据保存一个快照, 保存在数据表
undo-log中 - 当执行完毕后回向TC报告事务状态
- TM会向TC报告事务的状态
- TC会检测事务状态,都成功会删除log快照,失败则回滚从数据库中恢复快照
那么万一有其他线程这时候修改了数据怎么办呢???
简述AT模式与XA模式最大的区别是什么?
XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。XA模式强一致;AT模式最终一致
快照数据的版本检查
Seata在回滚时会检查快照数据的版本是否与当前数据一致。如果发现数据已经被其他事务修改,Seata会抛出异常,阻止回滚操作。这种机制可以避免数据被错误覆盖,但会导致事务回滚失败,需要额外的处理逻辑。补偿机制:如果回滚失败,Seata会尝试通过补偿机制(如补偿SQL)来恢复数据。补偿SQL是根据业务逻辑预先定义的,用于在回滚失败时尽可能恢复数据的一致性。
五、MQ基础
面试考点来了嘿嘿
5.1 异步调用
异步调用方式其实就是基于消息通知的方式,一般包含三个角色:
- 消息发送者:投递消息的人,就是原来的调用方
- 消息Broker:管理、暂存、转发消息,你可以把它理解成微信服务器
- 消息接收者:接收和处理消息的人,就是原来的服务提供方
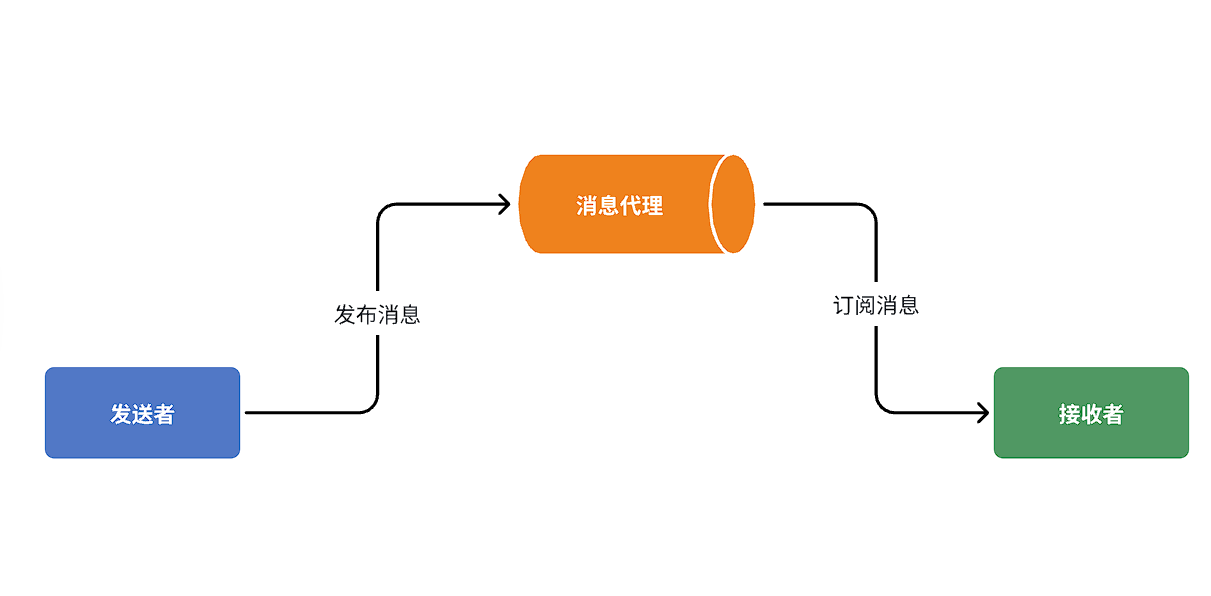
在异步调用中,发送者不再直接同步调用接收者的业务接口,而是发送一条消息投递给消息Broker。然后接收者根据自己的需求从消息Broker那里订阅消息。每当发送方发送消息后,接受者都能获取消息并处理。
这样,发送消息的人和接收消息的人就完全解耦了。
还是以余额支付业务为例:
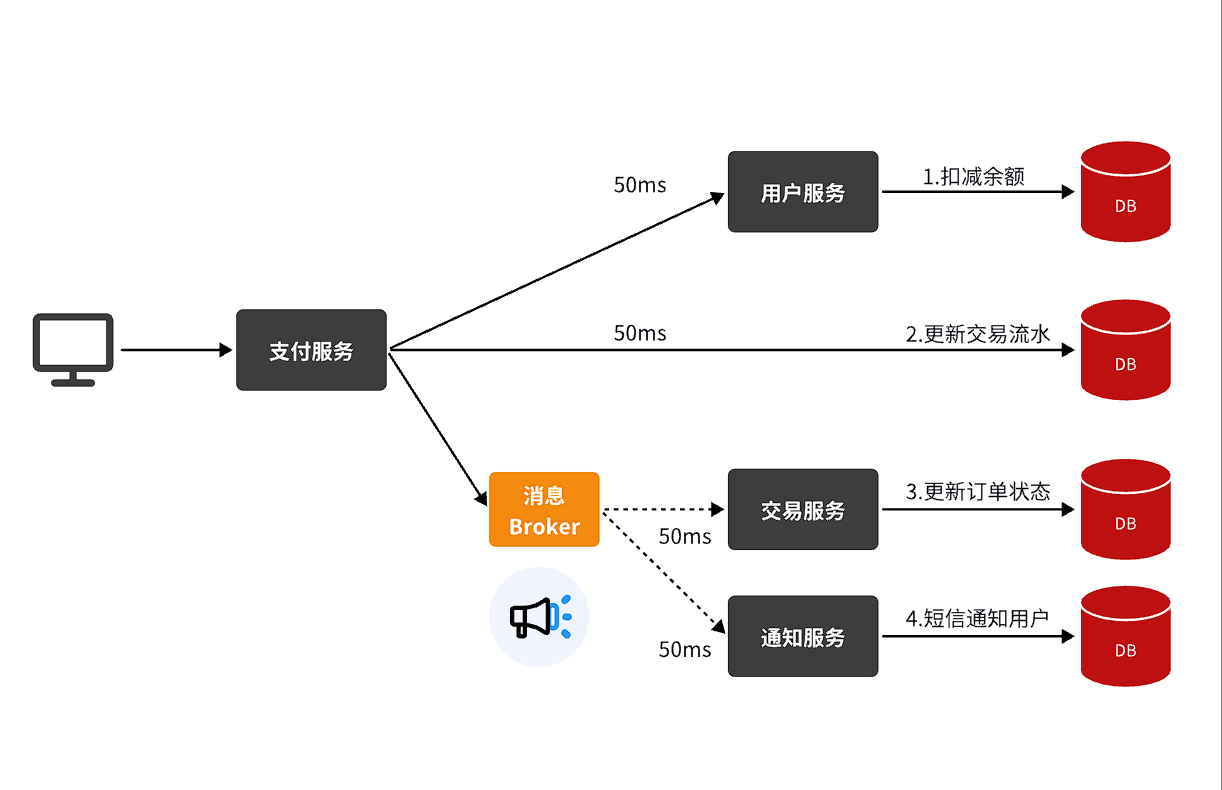
除了扣减余额、更新支付流水单状态以外,其它调用逻辑全部取消。而是改为发送一条消息到Broker。而相关的微服务都可以订阅消息通知,一旦消息到达Broker,则会分发给每一个订阅了的微服务,处理各自的业务。
假如产品经理提出了新的需求,比如要在支付成功后更新用户积分。支付代码完全不用变更,而仅仅是让积分服务也订阅消息即可:
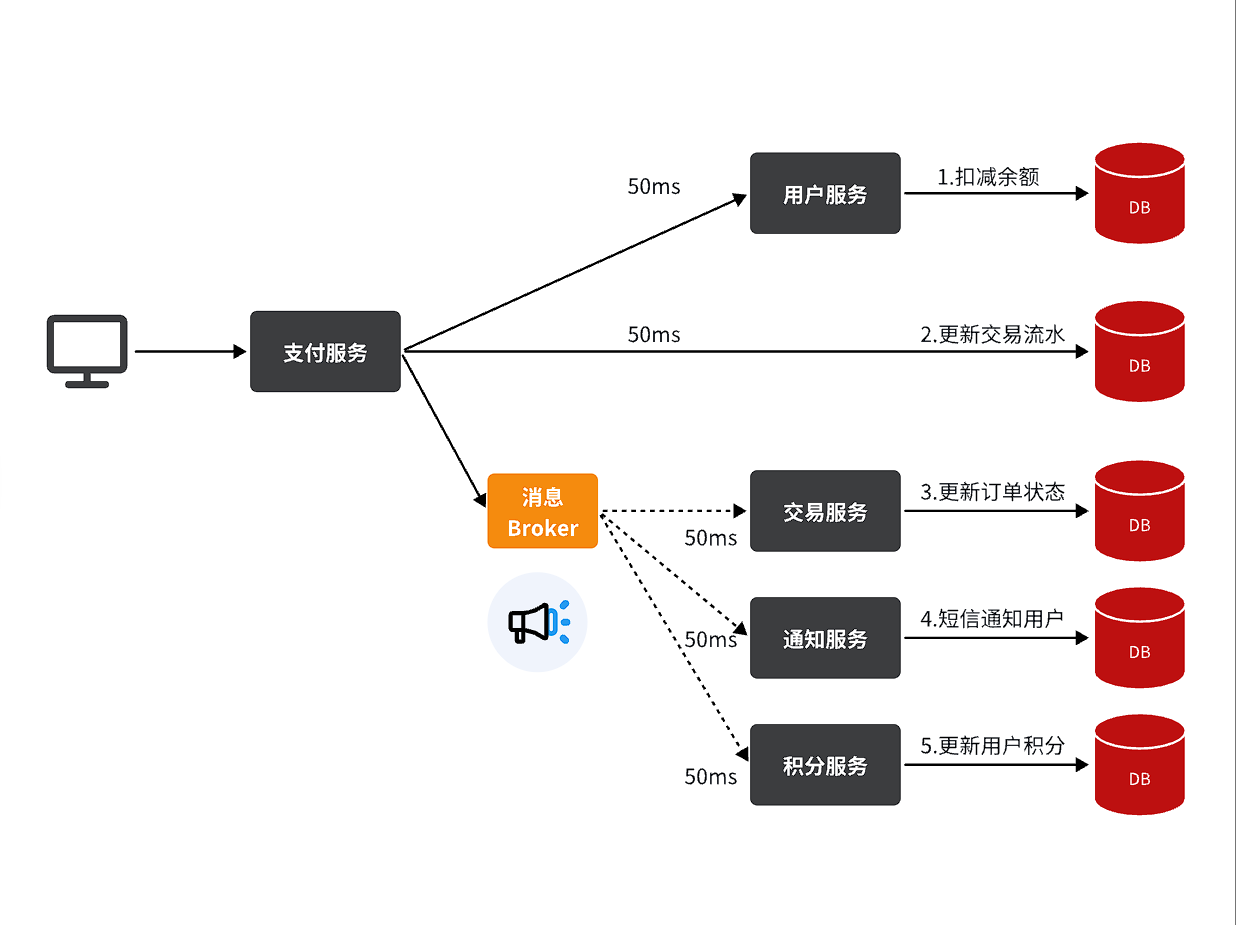
不管后期增加了多少消息订阅者,作为支付服务来讲,执行问扣减余额、更新支付流水状态后,发送消息即可。业务耗时仅仅是这三部分业务耗时,仅仅100ms,大大提高了业务性能。
另外,不管是交易服务、通知服务,还是积分服务,他们的业务与支付关联度低。现在采用了异步调用,解除了耦合,他们即便执行过程中出现了故障,也不会影响到支付服务。
- 交易服务、通知服务、积分服务收到Broker的消息后,如果业务代码没有执行成功broker还会再给服务发消息直到成功执行为止。
- 为了使用mq实现分布式事务,不能将mq发送消息的代码加入到事务中,比如像rabbitmq不支持rollback回滚操作的。此时可以配合分布式事务seata中的事务钩子,定义一个发送消息的方法,每当事务成功的时候,就可以发送消息。
综上,异步调用的优势包括:
- 耦合度更低
- 性能更好
- 业务拓展性强
- 故障隔离,避免级联失败
- 缓存消息,流量削峰填谷
当然,异步通信也并非完美无缺,它存在下列缺点:
- 完全依赖于Broker的可靠性、安全性和性能
- 架构复杂,后期维护和调试麻烦
5.2 技术选型
消息Broker,目前常见的实现方案就是消息队列(MessageQueue),简称为MQ.
目比较常见的MQ实现:
- ActiveMQ
- RabbitMQ
- RocketMQ
- Kafka
几种常见MQ的对比
| RabbitMQ | ActiveMQ | RocketMQ | Kafka | |
|---|---|---|---|---|
| 公司/社区 | Rabbit | Apache | 阿里 | Apache |
| 开发语言 | Erlang | Java | Java | Scala&Java |
| 协议支持 | AMQP,XMPP,SMTP,STOMP | OpenWire,STOMP,REST,XMPP,AMQP | 自定义协议 | 自定义协议 |
| 可用性 | 高 | 一般 | 高 | 高 |
| 单机吞吐量 | 一般 | 差 | 高 | 非常高 |
| 消息延迟 | 微秒级 | 毫秒级 | 毫秒级 | 毫秒以内 |
| 消息可靠性 | 高 | 一般 | 高 | 一般 |
追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
据统计,目前国内消息队列使用最多的还是RabbitMQ,再加上其各方面都比较均衡,稳定性也好,因此我们选择RabbitMQ来学习。
5.3 RabbitMQ
5.3.1 安装
docker run \ |
然后访问http://192.168.150.101:15672即可看到管理控制台。首次访问需要登录,默认的用户名和密码在配置文件中已经指定了。
RabbitMQ对应的架构:
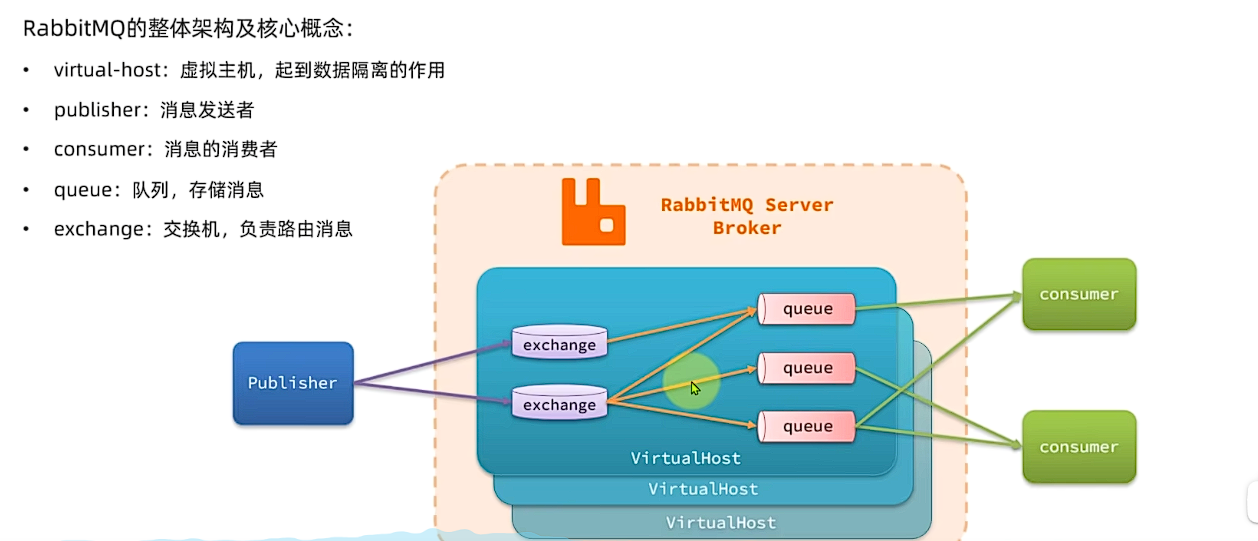
其中包含几个概念:
publisher:生产者,也就是发送消息的一方consumer:消费者,也就是消费消息的一方queue:队列,存储消息。生产者投递的消息会暂存在消息队列中,等待消费者处理exchange:交换机,负责消息路由。生产者发送的消息由交换机决定投递到哪个队列。(区分计网中的交换机:RabbitMQ的交换机是用于消息传递的,而计网的交换机是用于数据包传输的。)virtual host:虚拟主机,起到数据隔离的作用。每个虚拟主机相互独立,有各自的exchange、queue(每个虚拟主机相当于一个数据库,彼此之间互不影响)
5.3.2 Spring AMQP
将来我们开发业务功能的时候,肯定不会在控制台收发消息,而是应该基于编程的方式。由于RabbitMQ采用了AMQP协议,因此它具备跨语言的特性。任何语言只要遵循AMQP协议收发消息,都可以与RabbitMQ交互。并且RabbitMQ官方也提供了各种不同语言的客户端。
但是,RabbitMQ官方提供的Java客户端编码相对复杂,一般生产环境下我们更多会结合Spring来使用。而Spring的官方刚好基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP。并且还基于SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAMQP提供了三个功能:
- 自动声明队列、交换机及其绑定关系(设置队列)
- 基于注解的监听器模式,异步接收消息(设置消费端)
- 封装了RabbitTemplate工具,用于发送消息(设置生产端)
5.3.2.1 WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。
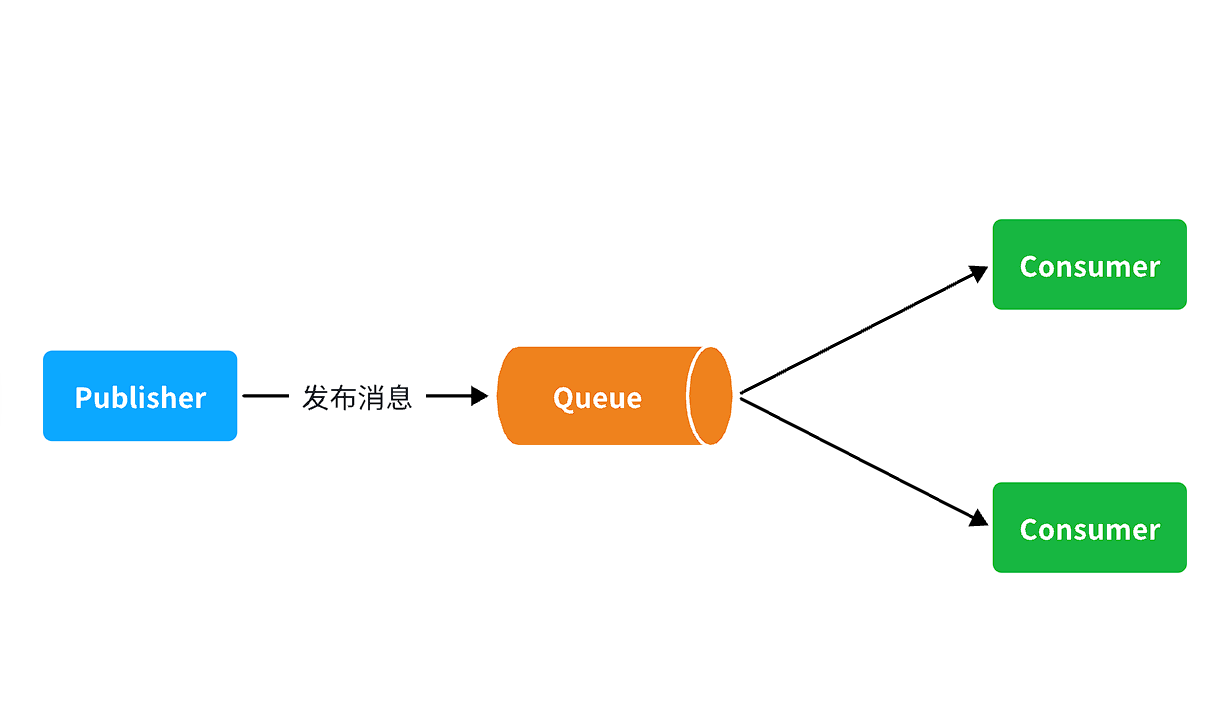
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
5.3.2.2 交换机
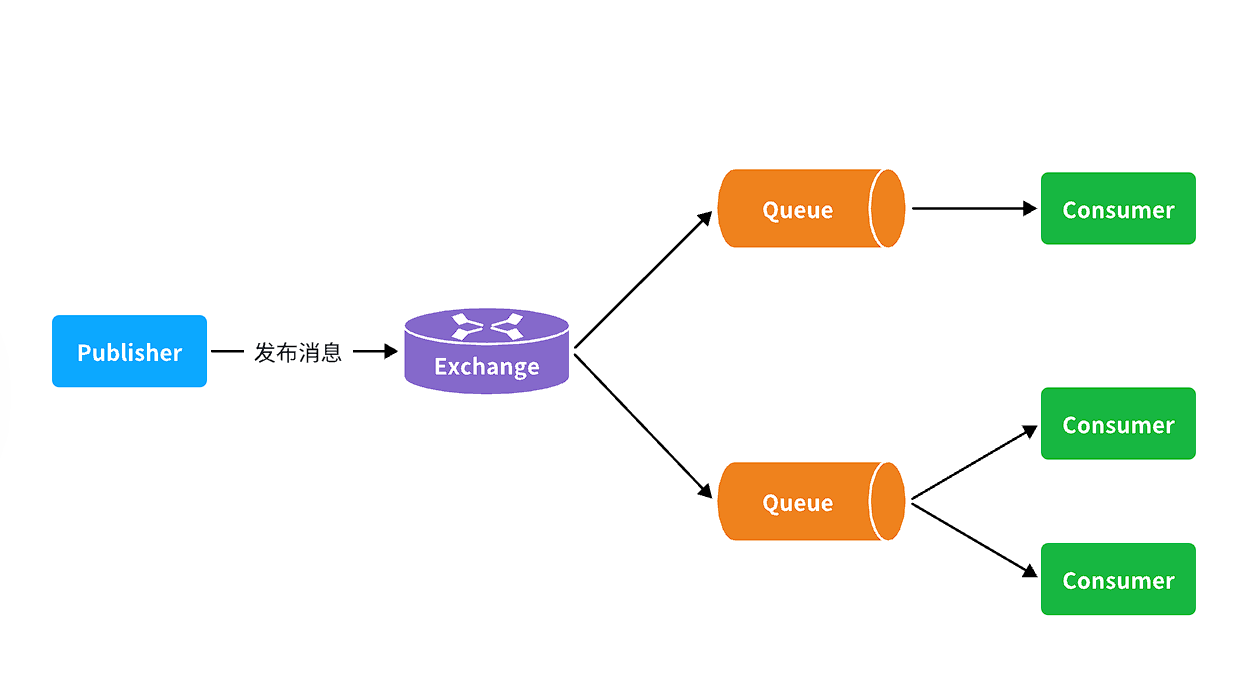
可以看到,在订阅模型中,多了一个exchange角色,而且过程略有变化:
- Publisher:生产者,不再发送消息到队列中,而是发给交换机
- Exchange:交换机,一方面,接收生产者发送的消息。另一方面,知道如何处理消息,例如递交给某个特别队列、递交给所有队列、或是将消息丢弃。到底如何操作,取决于Exchange的类型。
- Queue:消息队列也与以前一样,接收消息、缓存消息。不过队列一定要与交换机绑定。
- Consumer:消费者,与以前一样,订阅队列,没有变化
Exchange(交换机)只负责转发消息,不具备存储消息的能力,因此如果没有任何队列与Exchange绑定,或者没有符合路由规则的队列,那么消息会丢失!(引入Exchange的目的是为了在Rabbitmq中一个消息能够分发给多个queue中被不同的消费者服务多次消费,比如你一个订单信息需要加积分,加经验,这下可以分为两个queue来执行)
交换机的类型有四种:
- Fanout:广播,将消息交给所有绑定到交换机的队列。我们最早在控制台使用的正是Fanout交换机
- Direct:订阅,基于RoutingKey(路由key)发送给订阅了消息的队列
- Topic:通配符订阅,与Direct类似,只不过RoutingKey可以使用通配符
- Headers:头匹配,基于MQ的消息头匹配,用的较少。
5.3.2.3 Fanout 交换机
Fanout Exchange 会将接收到的消息路由到每一个跟其绑定的queue,所以也叫广播模式
5.3.2.4 Direct 交换机
Direct Exchange 会将接收到的消息根据规则路由到指定的Queue,因此称为定向路由。
- 每一个Queue都与Exchange设置一个BindingKey
- 发布者发送消息时,指定消息的RoutingKey
- Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
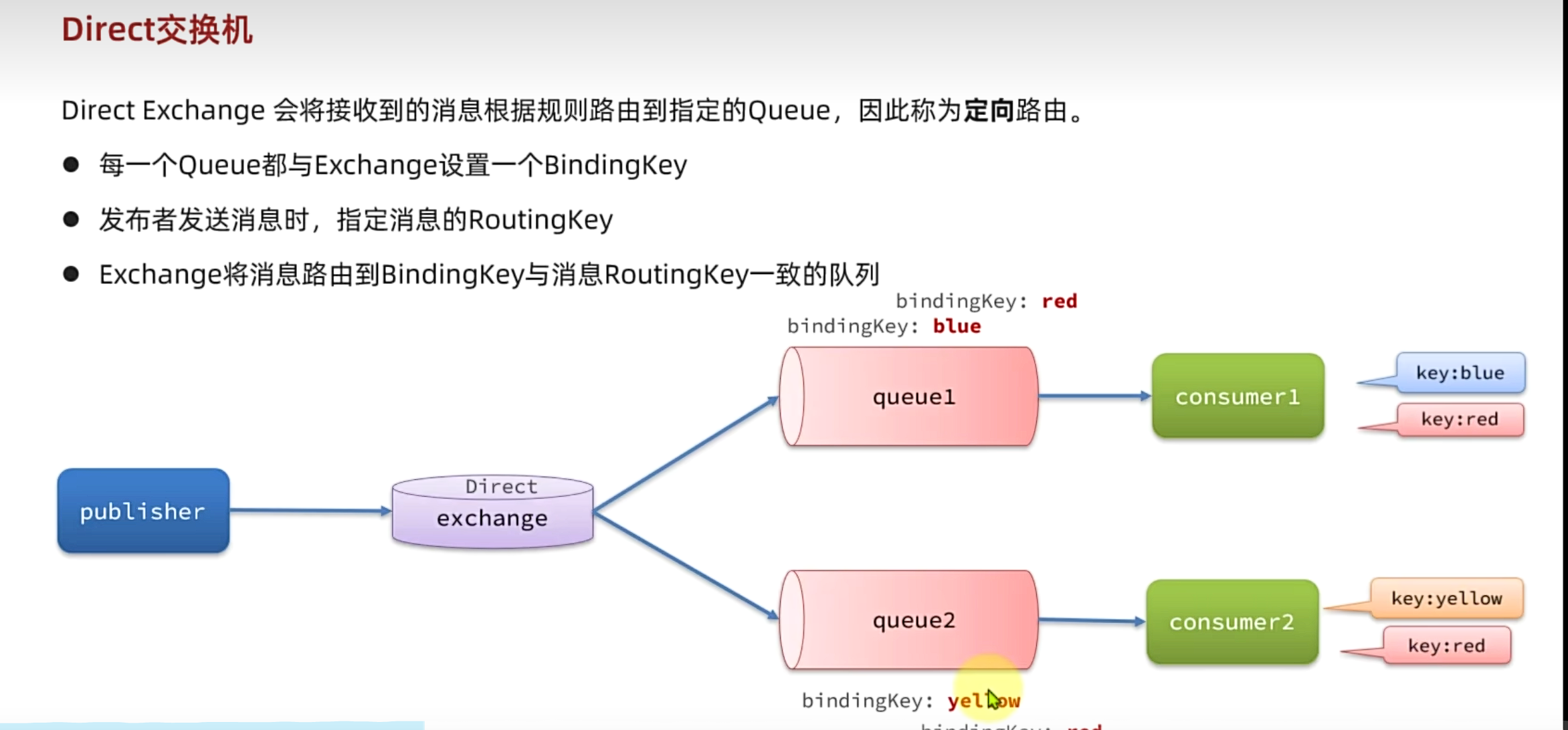
描述下Direct交换机与Fanout交换机的差异?
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
5.3.2.5 Topic交换机
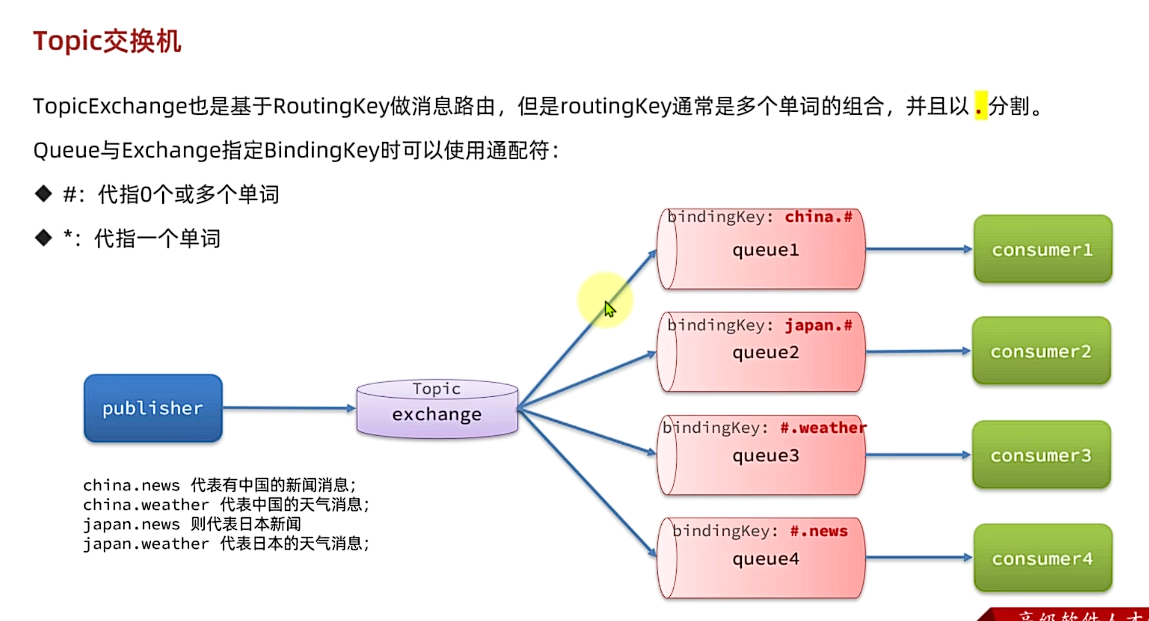
TopicExchange也是基于RoutingKey做消息路由,但是routingKey通常是多个单词的组合,并且以.分割。
Queue与Exchange指定BindingKey时可以使用通配符
- #:代指0个或多个单词
- *: 代指一个单词
5.3.2.6 声明队列和交换机
在之前我们都是基于RabbitMQ控制台来创建队列、交换机。但是在实际开发时,队列和交换机是程序员定义的,将来项目上线,又要交给运维去创建。那么程序员就需要把程序中运行的所有队列和交换机都写下来,交给运维。在这个过程中是很容易出现错误的。
因此推荐的做法是由程序启动时检查队列和交换机是否存在,如果不存在自动创建。
如果交换机或队列不存在
Spring AMQP会自动创建它们:
如果交换机(Exchange)不存在,Spring AMQP会根据注解中的配置(如名称和类型)自动创建交换机。
如果队列(Queue)不存在,Spring AMQP会根据注解中的配置(如名称)自动创建队列。
如果绑定关系(Binding)不存在,Spring AMQP会根据注解中的配置(如路由键)自动建立绑定关系。
如果交换机或队列已经存在
不会更改已存在的交换机或队列:
如果交换机或队列已经存在,并且它们的配置(如名称、类型等)与注解中的配置一致,Spring AMQP不会对它们进行任何更改。
如果交换机或队列的配置与注解中的配置不一致(例如,交换机类型不同或队列的持久性设置不同),RabbitMQ会抛出错误,导致声明失败。
|
再试试Topic模式:
|
5.3.2.7 消息转换器
当使用 Spring 发送消息时,传输内容通常是 Java 对象,但消息队列只能处理字节数据。因此,需要先将对象序列化为字节发送,接收时再反序列化为对象。Spring 默认使用的是 JDK 的序列化机制,但这种方式格式不友好、体积大、不安全。实际开发中,通常会配置 JSON 转换器,使消息更轻量、可读且更安全。
导入依赖
<dependency> |
然后添加一个Bean
|
5.3.2.8 订单业务
案例需求:改造余额支付功能,将支付成功后基于OpenFeign的交易服务的更新订单状态接口的同步调用,改为基于RabbitMQ的异步通知。
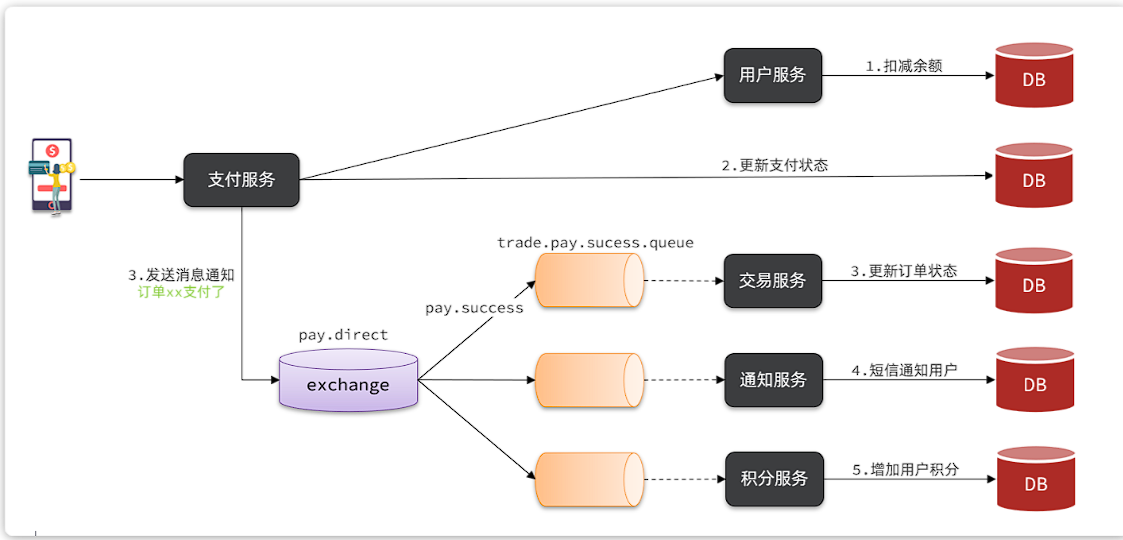
说明:目前没有通知服务和积分服务,因此我们只关注交易服务,步骤如下:
- 定义
direct类型交换机,命名为pay.direct - 定义消息队列,命名为
trade.pay.success.queue - 将
trade.pay.success.queue与pay.direct绑定,BindingKey为pay.success - 支付成功时不再调用交易服务更新订单状态的接口,而是发送一条消息到
pay.direct,发送消息的RoutingKey为pay.success,消息内容是订单id - 交易服务监听
trade.pay.success.queue队列,接收到消息后更新订单状态为已支付
不管是生产者还是消费者,都需要配置MQ的基本信息。分为两步:
1)添加依赖:
<!--消息发送--> |
2)配置MQ地址:
spring: |
4.1.接收消息
在trade-service服务中定义一个消息监听类:
其代码如下:
package com.hmall.trade.listener; |
4.2.发送消息
修改pay-service服务下的com.hmall.pay.``service``.impl.``PayOrderServiceImpl类中的tryPayOrderByBalance方法:
private final RabbitTemplate rabbitTemplate; |
六、 MQ高级
1.发送者的可靠性

1.1 发送者重连
首先第一种情况,就是生产者发送消息时,出现了网络故障,导致与MQ的连接中断。
为了解决这个问题,SpringAMQP提供的消息发送时的重试机制。即:当RabbitTemplate与MQ连接超时后,多次重试。
修改publisher模块的application.yaml文件,添加下面的内容:
spring: |
当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
1.2 发送者确认
SpringAMQP提供了Publisher Confirm和Publisher Return两种确认机制。开启确机制认后,当发送者发送消息给MQ后,MQ会返回确认结果给发送者。返同的结里有以下几种情况
一般情况下,只要生产者与MQ之间的网路连接顺畅,基本不会出现发送消息丢失的情况,因此大多数情况下我们无需考虑这种问题。
不过,在少数情况下,也会出现消息发送到MQ之后丢失的现象,比如:
- MQ内部处理消息的进程发生了异常
- 生产者发送消息到达MQ后未找到
Exchange - 生产者发送消息到达MQ的
Exchange后,未找到合适的Queue,因此无法路由
针对上述情况,RabbitMQ提供了生产者消息确认机制,包括Publisher Confirm和Publisher Return两种。在开启确认机制的情况下,当生产者发送消息给MQ后,MQ会根据消息处理的情况返回不同的回执。
具体如图所示:
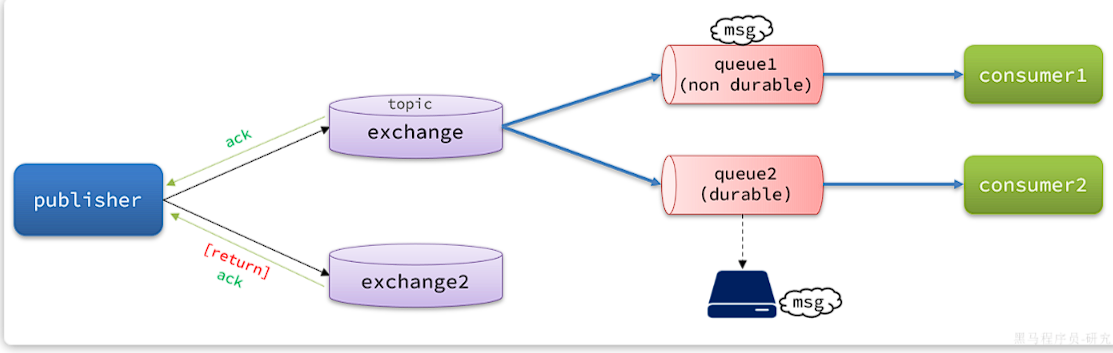
总结如下:
当消息投递到MQ,但是路由失败时,通过Publisher Return返回异常信息,同时返回ack的确认信息,代表投递成功
临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
其它情况都会返回NACK,告知投递失败
其中
ack和nack属于Publisher Confirm机制,ack是投递成功;nack是投递失败。而return则属于Publisher Return机制。默认两种机制都是关闭状态,需要通过配置文件来开启。
return和confirm机制是可以同时开启的。return机制:确认消息是否从 Exchange 路由到 Queue。confirm机制:确认消息是否到达 Exchange。若同时开启,路由失败(队列不存在或者交换机配置错误)时return机制返回异常信息以及消息,confirm机制则返回ack(不是nack)。两个机制不会互相影响。ack和nack都是由confirm机制返回的。
路由失败(交换机到队列),才触发ReturnCallback机制,返回异常信息;消息投递(发送者到交换机)成功,ConfirmCallback机制返回ack,投递失败返回nck
Publisher Confirm 机制用于向生产者确认消息是否成功送达队列。当生产者向 RabbitMQ 发送消息时,RabbitMQ 会返回一个唯一的交付标签(Delivery Tag),生产者可以通过这个标签来查询消息的投递状态。Publisher Return 机制用于处理无法路由的消息。当生产者向 RabbitMQ 发送一条消息时,如果消息无法被正确路由(例如由于队列不存在或交换机配置错误),RabbitMQ 会将该消息返回给生产者,并附带一个错误信息。
开启生产者确认
在publisher模块的application.yaml中添加配置:
spring: |
这里publisher-confirm-type有三种模式可选:
none:关闭confirm机制simple:同步阻塞等待MQ的回执correlated:MQ异步回调返回回执
一般我们推荐使用correlated,回调机制。
ReturnCallback
每个RabbitTemplate只能配置一个ReturnCallback,因此我们可以在配置类中统一设置。我们在publisher模块定义一个配置类:
ReturnCallback 的作用:当消息发送到交换机时,如果交换机无法将消息路由到任何队列(例如,路由键不匹配或队列不存在),RabbitMQ 会返回一个 Return 消息。ReturnCallback 就是用来处理这种场景的。
配置类 MqConfig 中设置了一个消息返回的回调处理机制。当发送的消息因为某些原因未能成功投递到目标队列时(如交换机、路由键不匹配等),rabbitTemplate 会触发 ReturnedMessage 回调,并通过日志记录详细的错误信息。这样你可以通过日志详细了解失败的原因,便于排查问题。
内容如下:
|
ConfirmCallback
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数:
这里的CorrelationData中包含两个核心的东西:
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
为什么returnCallback只用写一次配置,而ConfirmCallback需要每次都写,因为消息需要被确认,并且是每条消息都需要被确认
我们新建一个测试,向系统自带的交换机发送消息,并且添加ConfirmCallback:
|
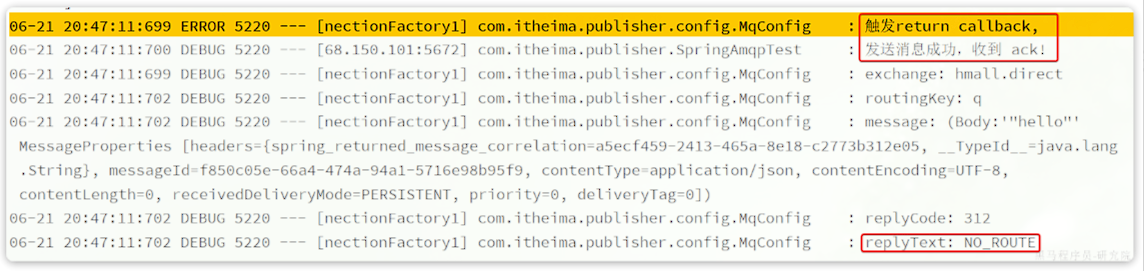
可以看到,由于传递的RoutingKey是错误的,路由失败后,触发了return callback,同时也收到了ack。
当我们修改为正确的RoutingKey以后,就不会触发return callback了,只收到ack。
而如果连交换机都是错误的,则只会收到nack。
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
- 路由失败:一般是因为RoutingKey错误导致,往往是编程导致
- 交换机名称错误:同样是编程错误导致
- MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
2. MQ的可靠性
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。这样会导致两个问题.
- 一旦MQ宕机,内存中的消息会丢失
- 内存空间有限,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞
mq在内存满的情况下,会持久化一部分到磁盘,然而这个过程较为耗时,这个过程中的消息发过来则就相当于丢失了。这个过程是阻塞式的,mq就不能处理消息了。每一次把消息从内存写出到磁盘,做page out的过程中,mq处于阻塞状态,消息处理会直接降为0。这就是基于内存带来的影响。所以需要将消息设置为持久化的。
RabbitMQ如何保证消息的可靠性?
·首先通过配置可以让交换机、队列、以及发送的消息都持久化。这样队列中的消息会持久化到磁盘,MQ重启消息依然存在。
RabbitMQ在3.6版本引入了LazyQueue,并且在3.12版本后会称为队列的默认模式。LazyQueue会将所有消息都持久化。
·开启持久化和生产者确认时,RabbitMQ只有在消息持久化完成后才会给生产者返回ACK回执
2.1 数据持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
交换机持久化
队列持久化
消息持久化
说明:在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。
不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
2.2 Lazy Queue
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。但在某些特殊情况下,这会导致消息积压,比如:
- 消费者宕机或出现网络故障
- 消息发送量激增,超过了消费者处理速度
- 消费者处理业务发生阻塞
一旦出现消息堆积问题,RabbitMQ的内存占用就会越来越高,直到触发内存预警上限。此时RabbitMQ会将内存消息刷到磁盘上,这个行为成为PageOut. PageOut会耗费一段时间,并且会阻塞队列进程。因此在这个过程中RabbitMQ不会再处理新的消息,生产者的所有请求都会被阻塞。
为了解决这个问题,从RabbitMQ的3.6.0版本开始,就增加了Lazy Queues的模式,也就是惰性队列。惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(也就是懒加载)
- 支持数百万条的消息存储
而在3.12版本之后,LazyQueue已经成为所有队列的默认格式。因此官方推荐升级MQ为3.12版本或者所有队列都设置为LazyQueue模式。
- 之前的消息持久化以后,是内存里写一份的同时(内存里满了,会直接删除,不会再像之前一样阻塞了队列进行消息写入磁盘),磁盘里也写一份,这样接受处理消息的速度就下降了
- 如果消费者处理消息的速度很快时,那么就不会逐条那种去从磁盘里加载消息到内存,而是直接提前缓存一批消息到内存(最多2048条)
- 普通的持久化发一条写一条,写的日志文件,而不是消息体本身,消息体本身只有当内存中存的消满了之后,才会写入磁盘的。
- 使用惰性队列的性能更好的原因是接收到消息直接存入磁盘,避免了非持久化的情况下,内存满时需要向磁盘中Page out,此时mq不能接收消息。同时对磁盘的io进行了优化,使其效率更高
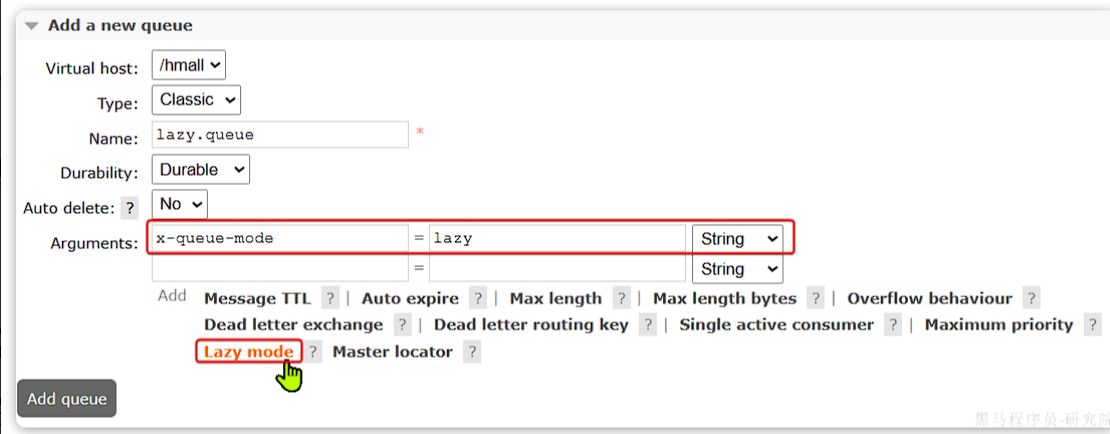
控制台配置Lazy模式
在添加队列的时候,添加x-queue-mod=lazy参数即可设置队列为Lazy模式:
代码配置Lazy模式
在利用SpringAMQP声明队列的时候,添加x-queue-mod=lazy参数也可设置队列为Lazy模式:
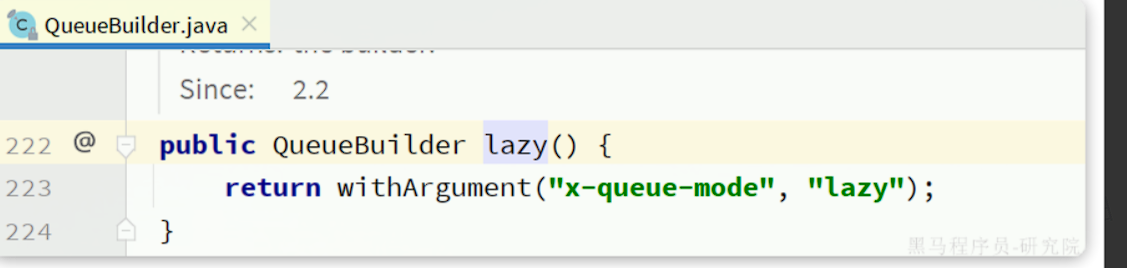
|
这里是通过QueueBuilder的lazy()函数配置Lazy模式,底层源码如下:
当然,我们也可以基于注解来声明队列并设置为Lazy模式:
|
更新已有队列为Lazy模式
对于已经存在的队列,也可以配置为lazy模式,但是要通过设置policy实现。
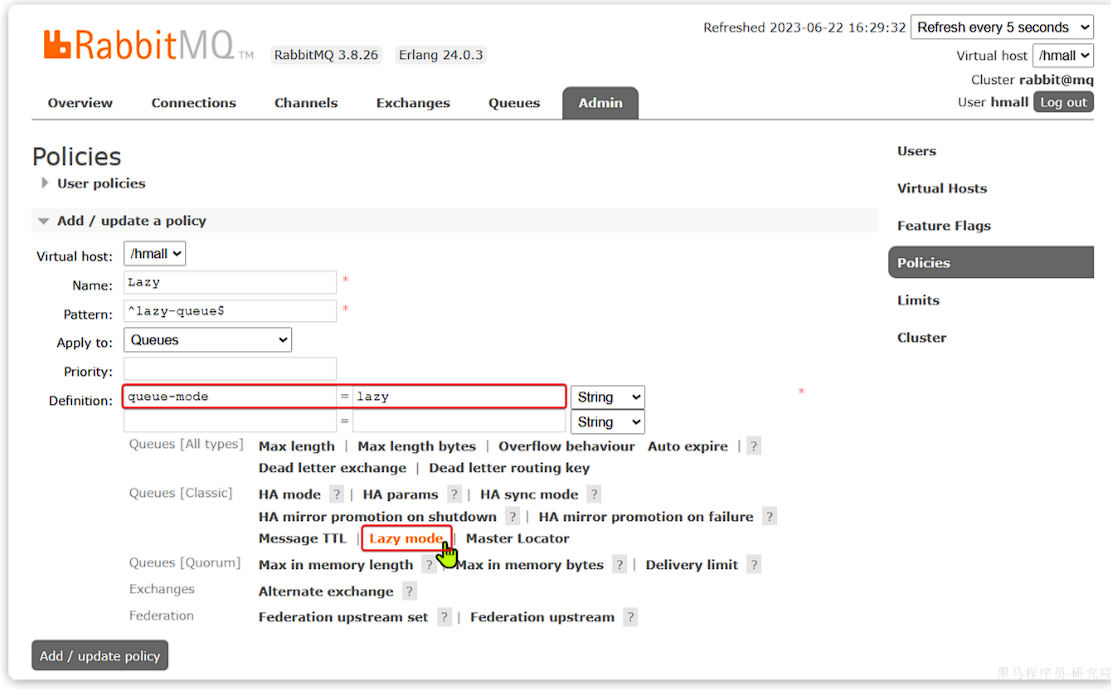
可以基于命令行设置policy:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues |
命令解读:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一个策略Lazy:策略名称,可以自定义"^lazy-queue$":用正则表达式匹配队列的名字'{"queue-mode":"lazy"}':设置队列模式为lazy模式--apply-to queues:策略的作用对象,是所有的队列
当然,也可以在控制台配置policy,进入在控制台的Admin页面,点击Policies,即可添加配置:
在RabbitMQ中,消息的持久性是由消息本身和队列的持久性决定的。如果消息没有被标记为持久化,那么即使队列本身是持久化的,在RabbitMQ服务器重启后,这些消息也会丢失。这里的关键点在于:
- 队列的持久性:持久化队列意味着队列的元数据(例如队列的名称、绑定关系等)会被存储到磁盘中,在RabbitMQ服务器重启时可以恢复队列的结构。但是,队列本身的持久性并不自动意味着队列中的消息会被持久化。
- 消息的持久性:如果消息在发送时没有设置为持久化,即没有将delivery node 设置为②(即持久化),则这些消息只会保存在内存中。当RabbitMQ服务器重启时,这些未持久化的消息会丢失,尽管队列本身可能被恢复。
- Lazy Queue: Lazy Queue是一种优化机制,它使得消息以最少的内存使用保存在磁盘上,即使是普通(非持久化)消息,也可以保存在磁盘上避免过多占用内存。它并不改变消息持久性的属性。也就是说,即使队列是Lazy类型的,如果消息没有被标记为持久化,消息仍然会在服务器重启时丢失。
总结
- 队列持久化:保存队列结构。
- 消息持久化:确保消息在RabbitMQ重启后不丢失。
- Lazy Queue:优化内存使用,减少对RAM的依赖,但消息如果未持久化,仍会丢失。
所以,即使是 Lazy Queue,如果消息没有被标记为持久化,那么这些消息在RabbitMQ服务器重启后仍然会丢失。
RabbitMQ 如何保证消息可靠性
- 首先通过配置可以让交换机、队列、以及发送的消息都持久化。这样队列中的消息会持久化到磁盘,MQ重启消息依然存在。
- RabbitMQ在3.6版本引入了LazyQueue,并且在3.12版本后会称为队列的默认模式。LazyQueue会将所有消息都持久化。
- 开启持久化和生产者确认时,RabbitMQ只有在消息持久化完成后才会给生产者返回ACK回执
3. 消费者可靠性
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
- 消息投递的过程中出现了网络故障
- 消费者接收到消息后突然宕机
- 消费者接收到消息后,因处理不当导致异常
- …
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态,一旦消息处理失败才能重新投递消息。
但问题来了:RabbitMQ如何得知消费者的处理状态呢?
3.1 消费者确认机制
消费者确认机制(Consumer Acknowledgement)是为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
一般reject方式用的较少,除非是消息格式有问题,那就是开发问题了。因此大多数情况下我们需要将消息处理的代码通过try catch机制捕获,消息处理成功时返回ack,处理失败时返回nack.
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:- 如果是业务异常,会自动返回
nack; - 如果是消息处理或校验异常,自动返回
reject;
- 如果是业务异常,会自动返回
由于消息回执的处理代码比较统一,因此SpringAMQP帮我们实现了消息确认。并允许我们通过配置文件设置ACK处理方式,有三种模式:
none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:- 如果是业务异常,会自动返回
nack; - 如果是消息处理或校验异常,自动返回
reject;
- 如果是业务异常,会自动返回
返回Reject的常见异常有:
Starting with version 1.3.2, the default ErrorHandler is now a ConditionalRejectingErrorHandler that rejects (and does not requeue) messages that fail with an irrecoverable error. Specifically, it rejects messages that fail with the following errors:
- o.s.amqp…MessageConversionException: Can be thrown when converting the incoming message payload using a MessageConverter.
- o.s.messaging…MessageConversionException: Can be thrown by the conversion service if additional conversion is required when mapping to a @RabbitListener method.
- o.s.messaging…MethodArgumentNotValidException: Can be thrown if validation (for example, @Valid) is used in the listener and the validation fails.
- o.s.messaging…MethodArgumentTypeMismatchException: Can be thrown if the inbound message was converted to a type that is not correct for the target method. For example, the parameter is declared as Message
but Message is received. - java.lang.NoSuchMethodException: Added in version 1.6.3.
- java.lang.ClassCastException: Added in version 1.6.3.
通过下面的配置可以修改SpringAMQP的ACK处理方式:
spring: |
修改consumer服务的SpringRabbitListener类中的方法,模拟一个消息处理的异常:
|
测试可以发现:当消息处理发生异常时,消息依然被RabbitMQ删除了。
我们再次把确认机制修改为auto:
spring: |
3.2 失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力:
Spring又提供了消费者失败重试机制:在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
修改consumer服务的application.yml文件,添加内容:
spring: |
重启consumer服务,重复之前的测试。可以发现:
- 消费者在失败后消息没有重新回到MQ无限重新投递,而是在本地重试了3次
- 本地重试3次以后,抛出了
AmqpRejectAndDontRequeueException异常。查看RabbitMQ控制台,发现消息被删除了,说明最后SpringAMQP返回的是reject
结论:
- 开启本地重试时,消息处理过程中抛出异常,不会requeue到队列,而是在消费者本地重试
- 重试达到最大次数后,Spring会返回reject,消息会被丢弃
3.3 失败处理机制
在之前的测试中,本地测试达到最大重试次数后,消息会被丢弃。这在某些对于消息可靠性要求较高的业务场景下,显然不太合适了。(开启retry之后,都失败reject后,MessageRecover的默认实现使得消息不requeue,从而被丢弃)
因此Spring允许我们自定义重试次数耗尽后的消息处理策略,这个策略是由MessageRecovery接口来定义的,它有3个不同实现:
RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机

比较优雅的一种处理方案是RepublishMessageRecoverer,失败后将消息投递到一个指定的,专门存放异常消息的队列,后续由人工集中处理。
1)在consumer服务中定义处理失败消息的交换机和队列
|
2)定义一个RepublishMessageRecoverer,关联队列和交换机
|
完整代码如下:
package com.itheima.consumer.config; |
3.4 业务幂等性
何为幂等性?
- 消息被重复消费,如果消费者和mq之间的网络连接断开,消费者的ack未能成功发送到mq,那么等到连接好了之后,mq又会重新发送消息,此时消息重复被消费。如果这个消息是用于扣减库存的,那么就会出现问题
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。
在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。例如:
- 根据id删除数据
- 查询数据
- 新增数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
- 取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况
- 退款业务。重复退款对商家而言会有经济损失。
所以,我们要尽可能避免业务被重复执行。
然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
- 页面卡顿时频繁刷新导致表单重复提交
- 服务间调用的重试
- MQ消息的重复投递
我们在用户支付成功后会发送MQ消息到交易服务,修改订单状态为已支付,就可能出现消息重复投递的情况。如果消费者不做判断,很有可能导致消息被消费多次,出现业务故障。
举例:
- 假如用户刚刚支付完成,并且投递消息到交易服务,交易服务更改订单为已支付状态。
- 由于某种原因,例如网络故障导致生产者没有得到确认,隔了一段时间后重新投递给交易服务。
- 但是,在新投递的消息被消费之前,用户选择了退款,将订单状态改为了已退款状态。
- 退款完成后,新投递的消息才被消费,那么订单状态会被再次改为已支付。业务异常。
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
- 唯一消息ID
- 业务状态判断
3.4.1 唯一消息id(白雪)
这个思路非常简单:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
我们该如何给消息添加唯一ID呢?
其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可。
以Jackson的消息转换器为例:
|
3.4.2 业务判断
业务判断就是基于业务本身的逻辑或状态来判断是否是重复的请求或消息,不同的业务场景判断的思路也不一样。
例如我们当前案例中,处理消息的业务逻辑是把订单状态从未支付修改为已支付。因此我们就可以在执行业务时判断订单状态是否是未支付,如果不是则证明订单已经被处理过,无需重复处理。
相比较而言,消息ID的方案需要改造原有的数据库,所以我更推荐使用业务判断的方案。
以支付修改订单的业务为例,我们需要修改OrderServiceImpl中的markOrderPaySuccess方法:
|
上述代码逻辑上符合了幂等判断的需求,但是由于判断和更新是两步动作,因此在极小概率下可能存在线程安全问题。
我们可以合并上述操作为这样:
|
注意看,上述代码等同于这样的SQL语句:
UPDATE `order` SET status = ? , pay_time = ? WHERE id = ? AND status = 1 |
我们在where条件中除了判断id以外,还加上了status必须为1的条件。如果条件不符(说明订单已支付),则SQL匹配不到数据,根本不会执行。
如何保证支付服务与交易服务订单状态的一致性
- 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同时也开启了MQ的持久化,避免因服务宕机导致消息丢失。
- 最后,我们还在交易服务更新订单状态时做了业务幂等判断,避免因消息重复消费导致订单状态异常。
3.5 兜底方案
虽然我们利用各种机制尽可能增加了消息的可靠性,但也不好说能保证消息100%的可靠。万一真的MQ通知失败该怎么办呢?
有没有其它兜底方案,能够确保订单的支付状态一致呢?
其实思想很简单:既然MQ通知不一定发送到交易服务,那么交易服务就必须自己主动去查询支付状态。这样即便支付服务的MQ通知失败,我们依然能通过主动查询来保证订单状态的一致。
流程如下:
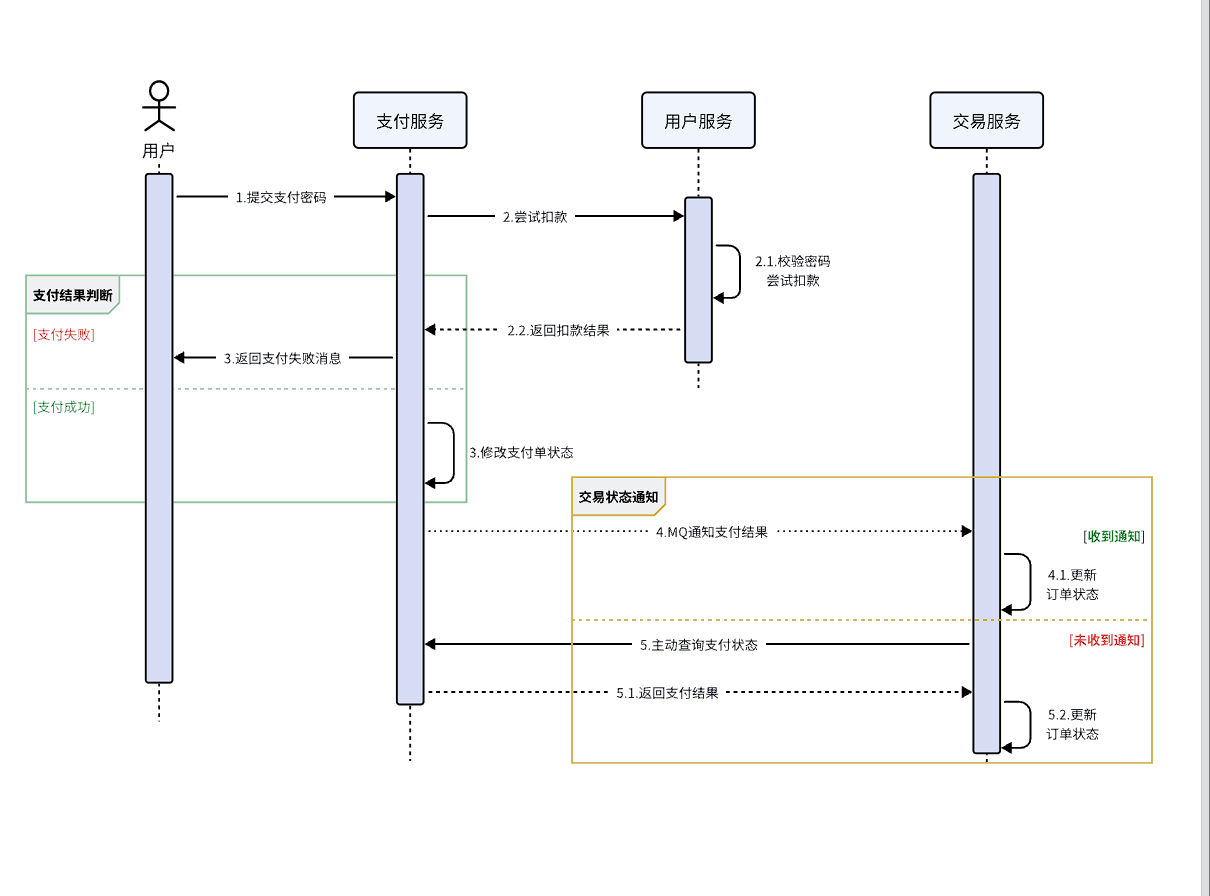
图中黄色线圈起来的部分就是MQ通知失败后的兜底处理方案,由交易服务自己主动去查询支付状态。
不过需要注意的是,交易服务并不知道用户会在什么时候支付,如果查询的时机不正确(比如查询的时候用户正在支付中),可能查询到的支付状态也不正确。
那么问题来了,我们到底该在什么时间主动查询支付状态呢?
这个时间是无法确定的,因此,通常我们采取的措施就是利用定时任务定期查询,例如每隔20秒就查询一次,并判断支付状态。如果发现订单已经支付,则立刻更新订单状态为已支付即可。
定时任务大家之前学习过,具体的实现这里就不再赘述了。
至此,消息可靠性的问题已经解决了。
综上,支付服务与交易服务之间的订单状态一致性是如何保证的?
- 首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递的可靠性
- 最后,我们还在交易服务设置了定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
4. 延迟消息
延迟消息∶发送者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息。

在电商的支付业务中,对于一些库存有限的商品,为了更好的用户体验,通常都会在用户下单时立刻扣减商品库存。例如电影院购票、高铁购票,下单后就会锁定座位资源,其他人无法重复购买。
但是这样就存在一个问题,假如用户下单后一直不付款,就会一直占有库存资源,导致其他客户无法正常交易,最终导致商户利益受损!
因此,电商中通常的做法就是:对于超过一定时间未支付的订单,应该立刻取消订单并释放占用的库存。
例如,订单支付超时时间为30分钟,则我们应该在用户下单后的第30分钟检查订单支付状态,如果发现未支付,应该立刻取消订单,释放库存。
但问题来了:如何才能准确的实现在下单后第30分钟去检查支付状态呢?
像这种在一段时间以后才执行的任务,我们称之为延迟任务,而要实现延迟任务,最简单的方案就是利用MQ的延迟消息了。
在RabbitMQ中实现延迟消息也有两种方案:
- 死信交换机+TTL(存活时间)
- 延迟消息插件
这一章我们就一起研究下这两种方案的实现方式,以及优缺点。
4.1 死信交换机(白雪)
当一个队列中的消息满足下列情况之一时,就会成为死信(dead letter) :
- ·消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
- ·消息是一个过期消息(达到了队列或消息本身设置的过期时间),超时无人消费
- ·要投递的队列消息堆积满了,最早的消息可能成为死信
如果一个队列中的消息已经成为死信,并且这个队列通过**dead-letter-exchange属性指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机就称为死信交换机**(Dead Letter Exchange)。而此时加入有队列与死信交换机绑定,则最终死信就会被投递到这个队列中。
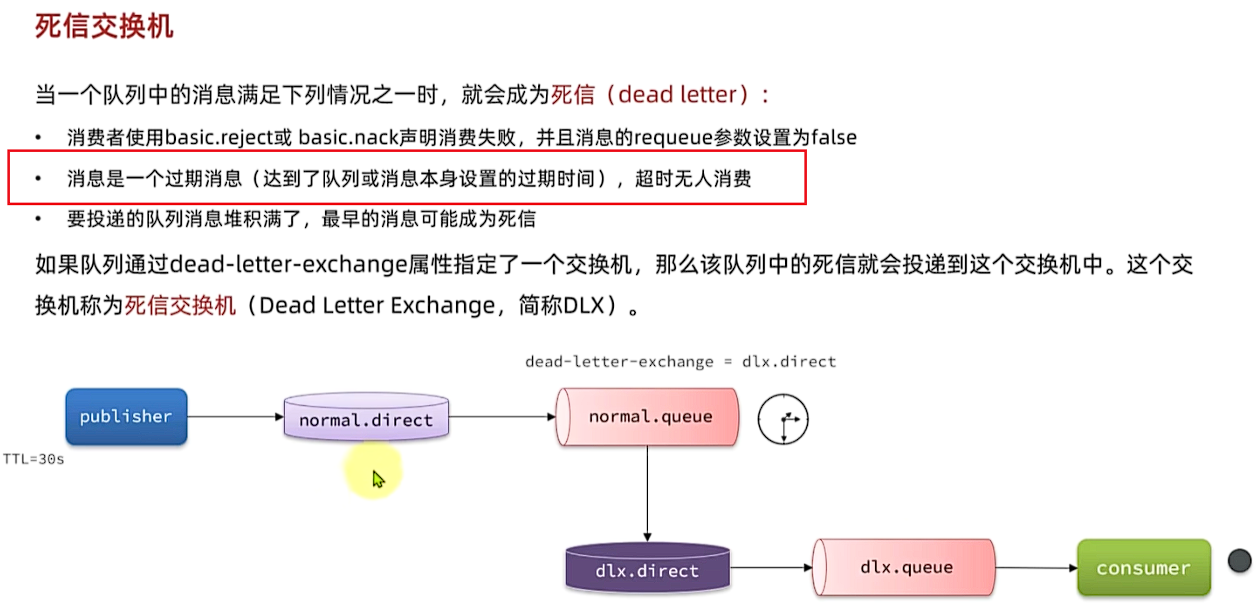
死信交换机有什么作用呢?
- 收集那些因处理失败而被拒绝的消息
- 收集那些因队列满了而被拒绝的消息
- 收集因TTL(有效期)到期的消息
前面两种作用场景可以看做是把死信交换机当做一种消息处理的最终兜底方案,与消费者重试时讲的RepublishMessageRecoverer作用类似。
而最后一种场景,大家设想一下这样的场景:
如图,有一组绑定的交换机(ttl.fanout)和队列(ttl.queue)。但是ttl.queue没有消费者监听,而是设定了死信交换机hmall.direct,而队列direct.queue1则与死信交换机绑定,RoutingKey是blue:
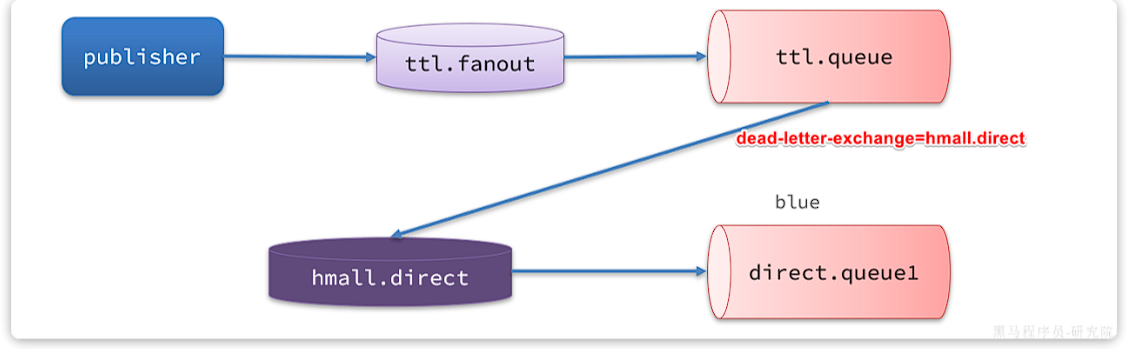
假如我们现在发送一条消息到ttl.fanout,RoutingKey为blue,并设置消息的有效期为5000毫秒:
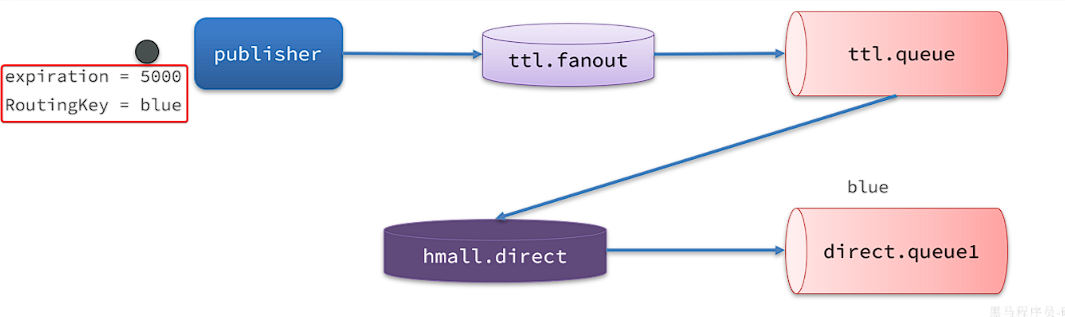
注意:尽管这里的ttl.fanout不需要RoutingKey,但是当消息变为死信并投递到死信交换机时,会沿用之前的RoutingKey,这样hmall.direct才能正确路由消息。
消息肯定会被投递到ttl.queue之后,由于没有消费者,因此消息无人消费。5秒之后,消息的有效期到期,成为死信:
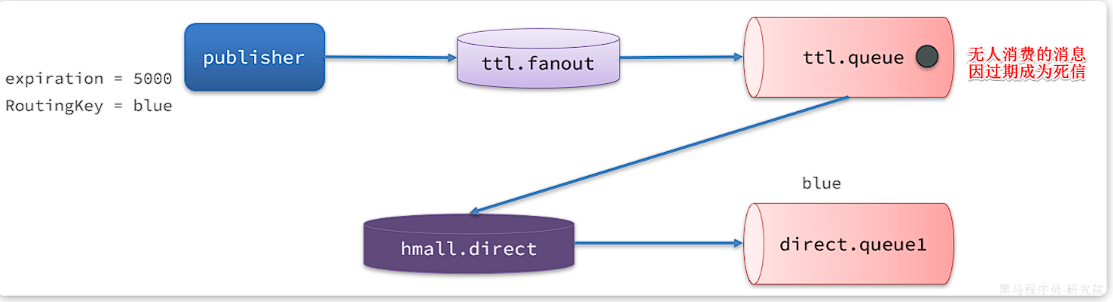
死信被再次投递到死信交换机hmall.direct,并沿用之前的RoutingKey,也就是blue:
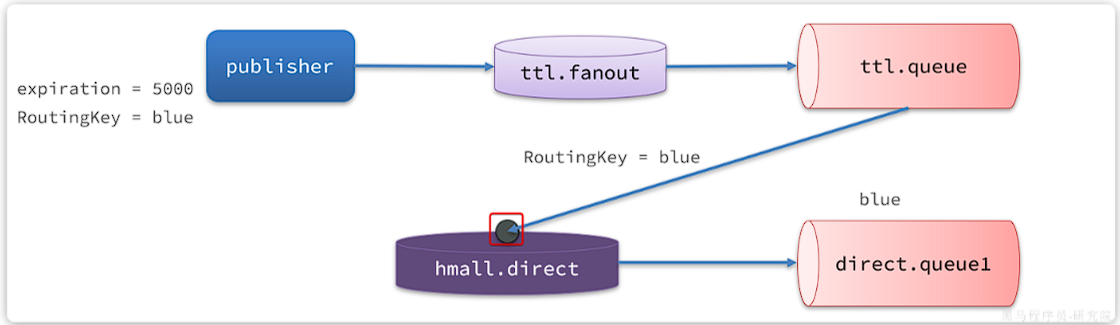
由于direct.queue1与hmall.direct绑定的key是blue,因此最终消息被成功路由到direct.queue1,如果此时有消费者与direct.queue1绑定, 也就能成功消费消息了。但此时已经是5秒钟以后了:
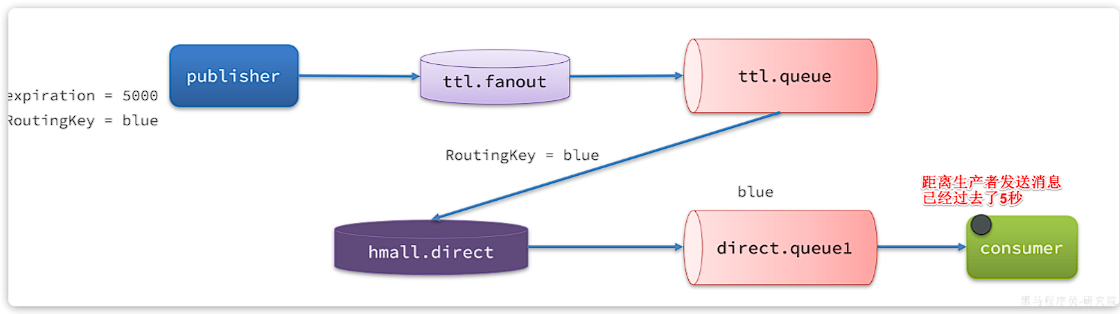
也就是说,publisher发送了一条消息,但最终consumer在5秒后才收到消息。我们成功实现了延迟消息。
这里的RoutingKey必须一致。死信在转移到死信队列时,他的Routing key 也会保存下来。但是如果配置了x-dead-letter-routing-key这 个参数的话,routingkey就会被替换为配置的这个值。 另外,死信在转移到死信队列的过程中,是没有经过消息发送者确认的,所以并不能保证消息的安全性。
RabbitMQ的消息过期是基于追溯方式来实现的,也就是说当一个消息的TTL到期以后不一定会被移除或投递到死信交换机,而是在消息恰好处于队首时才会被处理。
当队列中消息堆积很多的时候,过期消息可能不会被按时处理,因此你设置的TTL时间不一定准确。
4.2 DelayExchage插件
基于死信队列虽然可以实现延迟消息,但是太麻烦了。因此RabbitMQ社区提供了一个延迟消息插件来实现相同的效果。
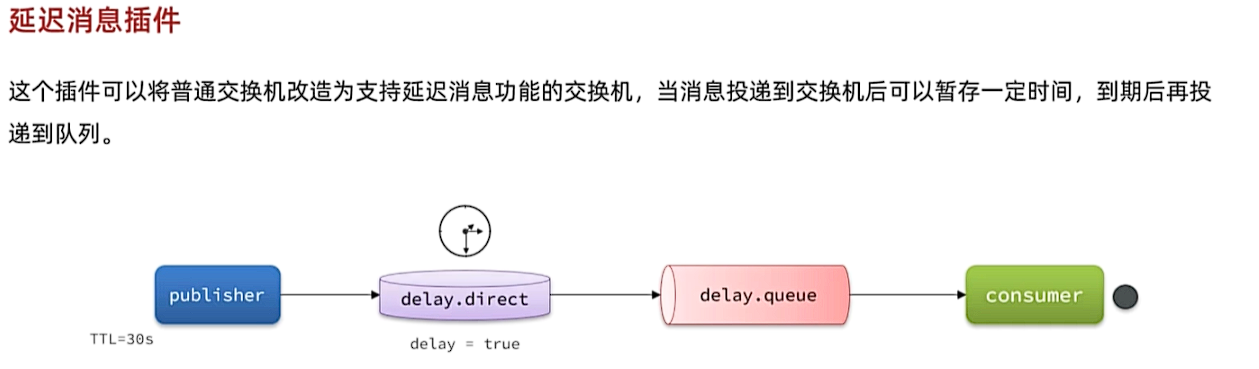
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
docker volume inspect mq-plugins |
结果如下:
[ |
插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。
接下来执行命令,安装插件:
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange |
运行结果如下:
声明延迟交换机
基于注解方式:
|
基于@Bean的方式:
package com.itheima.consumer.config; |
发送延迟消息
发送消息时,必须通过x-delay属性设定延迟时间:
|
延迟消息插件内部会维护一个本地数据库表,同时使用Elang Timers功能实现计时。如果消息的延迟时间设置较长,可能会导致堆积的延迟消息非常多,会带来较大的CPU开销,同时延迟消息的时间会存在误差。
因此,不建议设置延迟时间过长的延迟消息。
5.超时取消订单
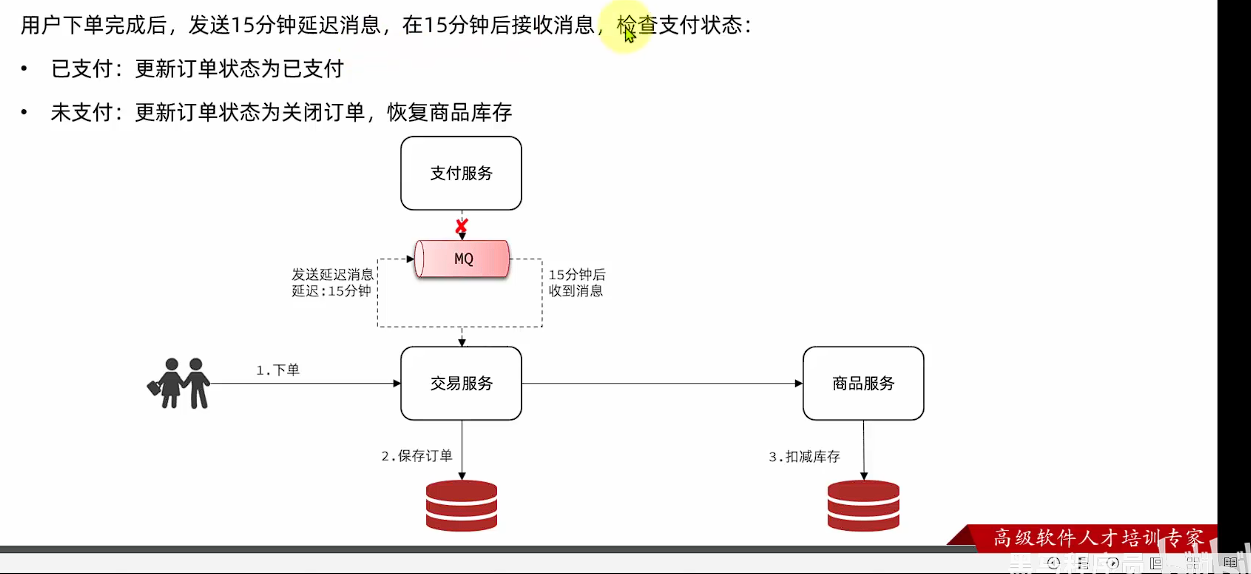
接下来,我们就在交易服务中利用延迟消息实现订单超时取消功能。其大概思路如下:
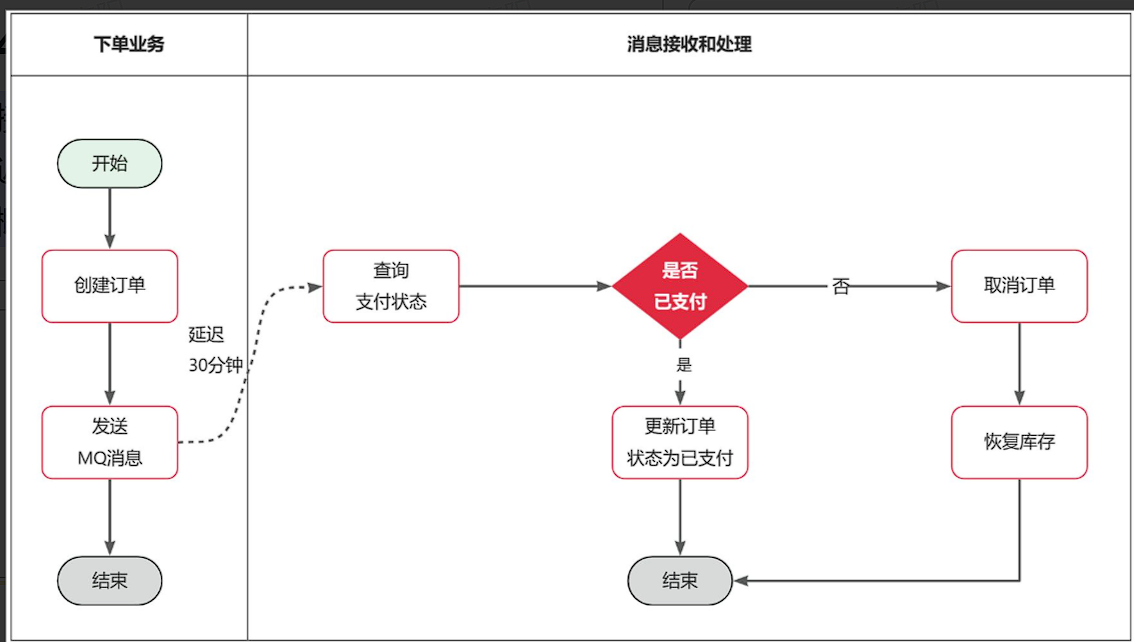
假如订单超时支付时间为30分钟,理论上说我们应该在下单时发送一条延迟消息,延迟时间为30分钟。这样就可以在接收到消息时检验订单支付状态,关闭未支付订单。
七、Elasticsearch 01
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
整套技术栈被称为ELK,经常用来做日志收集、系统监控和状态分析等等:
整套技术栈的核心就是用来存储、搜索、计算的Elasticsearch,因此我们接下来学习的核心也是Elasticsearch。
我们要安装的内容包含2部分:
- elasticsearch:存储、搜索和运算
- kibana:图形化展示
首先Elasticsearch不用多说,是提供核心的数据存储、搜索、分析功能的。
然后是Kibana,Elasticsearch对外提供的是Restful风格的API,任何操作都可以通过发送http请求来完成。不过http请求的方式、路径、还有请求参数的格式都有严格的规范。这些规范我们肯定记不住,因此我们要借助于Kibana这个服务。
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
- 对Elasticsearch数据的搜索、展示
- 对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
- 对Elasticsearch的集群状态监控
- 它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
1.安装
1.1 安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
docker run -d \ |
注意,这里我们采用的是elasticsearch的7.12.1版本,由于8以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本。
安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息:
通过下面的Docker命令,即可部署Kibana:
docker run -d \ |
2. 倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建正向索引
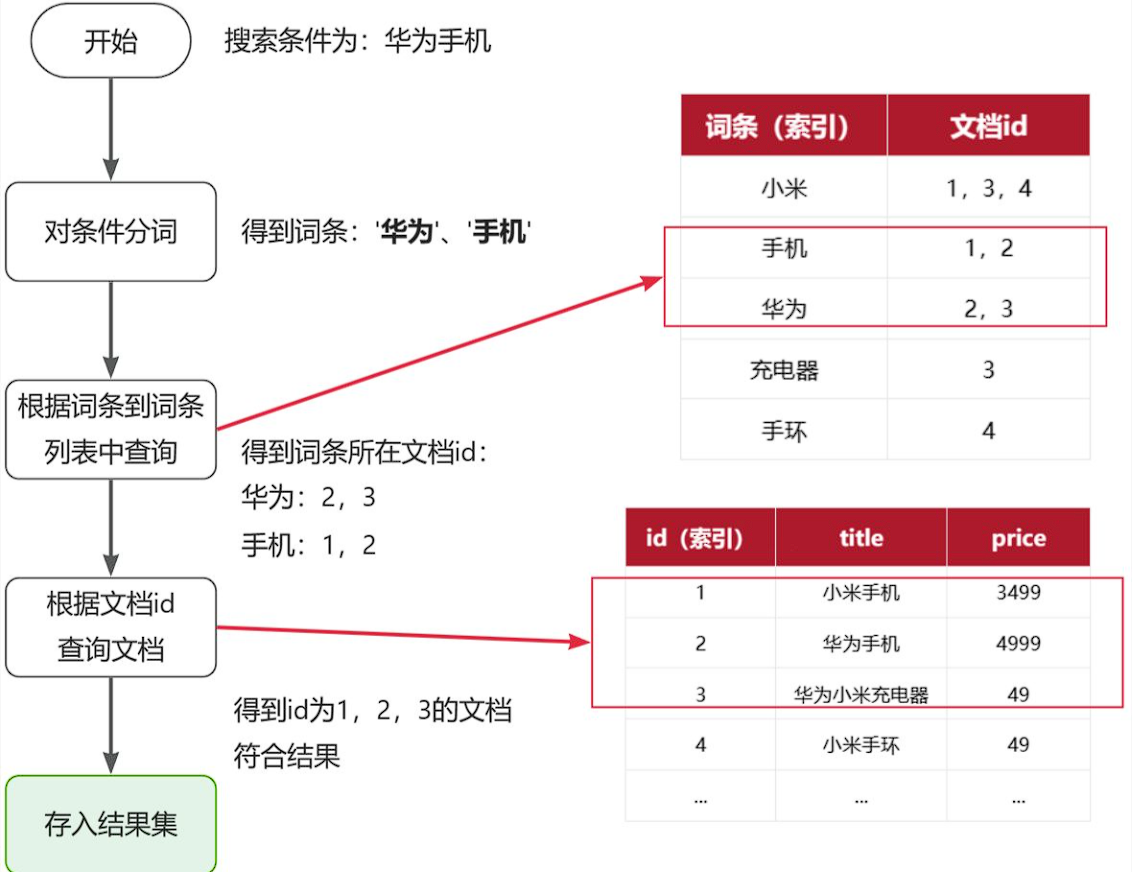
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询正向索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
正向和倒排
以索引的使用来理解:
正向索引,走的是全表扫描,速度很慢,而倒排,根据词条找文档id,可以走索引,再根据文档id找文档,也是索引,因此效率很高
那么为什么一个叫做正向索引,一个叫做倒排索引呢?
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
是不是恰好反过来了?
那么两者方式的优缺点是什么呢?
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
什么是正向索引?
- 基于文档id创建索引。根据id查询快,但是查询词条时必须先找到文档,而后判断是否包含词条
什么是倒排索引?
对文档内容分词,对词条创建索引,并记录词条所在文档的id。
查询时先根据词条查询到文档id,而后根据文档id查询文档
3. IK 分词器
3.1 安装
docker exec -it es ./bin/elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.12.1.zip |
最后,重启es容器:
docker restart es |
3.2 使用
IK分词器包含两种模式:
ik_smart:智能语义切分ik_max_word:最细粒度切分
我们在Kibana的DevTools上来测试分词器,首先测试Elasticsearch官方提供的标准分词器:
POST /_analyze |
结果如下:
{ |
可以看到,标准分词器智能1字1词条,无法正确对中文做分词。
我们再测试IK分词器:
POST /_analyze |
执行结果如下:
{ |
3.3 拓展词典
[root@192 volumes]# find / -name "IKAnalyzer.cfg.xml" |
在config目录下的ext.dic文件下即可添加新词
4. 基本概览
elasticsearch是面向**文档(Document)**存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:

因此,原本数据库中的一行数据就是ES中的一个JSON文档;而数据库中每行数据都包含很多列,这些列就转换为JSON文档中的字段(Field)。
索引和映射
随着业务发展,需要在es中存储的文档也会越来越多,比如有商品的文档、用户的文档、订单文档等等
所有文档都散乱存放显然非常混乱,也不方便管理。
因此,我们要将类型相同的文档集中在一起管理,称为索引(Index)。例如:
商品索引
{ |
用户索引
{ |
订单索引
{ |
- 所有用户文档,就可以组织在一起,称为用户的索引;
- 所有商品的文档,可以组织在一起,称为商品的索引;
- 所有订单的文档,可以组织在一起,称为订单的索引;
因此,我们可以把索引当做是数据库中的表。
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
索引:和mysql的表的概念类似
映射:索引中文档的字段约束信息,类似表的结构约束
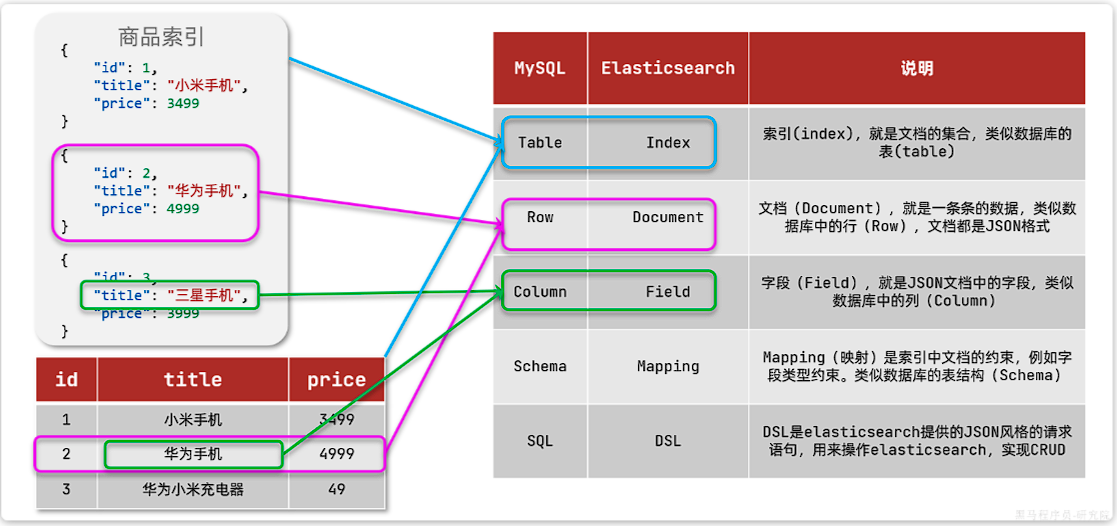
MySQL与elasticsearch
我们统一的把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
那是不是说,我们学习了elasticsearch就不再需要mysql了呢?
并不是如此,两者各自有自己的擅长之处:
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
5. 索引库的操作
Index就类似数据库表,Mapping映射就类似表的结构。我们要向es中存储数据,必须先创建Index和Mapping
Mapping 是 Elasticsearch 的“字段结构 + 建索引规则 + 分词逻辑 + 存储行为”的声明。就类似于你在mysql中写Create table这种语句
5.1 Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:
text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址) - 数值:
long、integer、short、byte、double、float、 - 布尔:
boolean - 日期:
date - 对象:
object
- 字符串:
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
例如下面的json文档:
{ |
对应的每个字段映射(Mapping):

5.2 索引的CRUD
由于Elasticsearch采用的是Restful风格的API,因此其请求方式和路径相对都比较规范,而且请求参数也都采用JSON风格。
我们直接基于Kibana的DevTools来编写请求做测试,由于有语法提示,会非常方便。

创建索引库和映射
基本语法:
- 请求方式:
PUT - 请求路径:
/索引库名,可以自定义 - 请求参数:
mapping映射
格式:
PUT /索引库名称 |
示例:
PUT /heima |
查询
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
格式:
GET /索引库名 |
示例:
GET /heima |
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
新字段会创建自己的倒排索引,与现有索引并行存在,不会干扰已索引的数据。
语法说明
PUT /索引库名/_mapping |
示例:
PUT /heima/_mapping |
删除
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
格式:
DELETE /索引库名 |
示例:
DELETE /heima |
总结
索引库操作有哪些?
- 创建索引库:PUT /索引库名
- 查询索引库:GET /索引库名
- 删除索引库:DELETE /索引库名
- 修改索引库,添加字段:PUT /索引库名/_mapping
可以看到,对索引库的操作基本遵循的Restful的风格,因此API接口非常统一,方便记忆。
6. 文档操作
有了索引库,接下来就可以向索引库中添加数据了。
Elasticsearch中的数据其实就是JSON风格的文档。操作文档自然包括增、删、改、查等几种常见操作,我们分别来学习。
新增
新增文档,就会按照索引库中的映射来创建倒排索引,但是创建倒排索引的过程对我们是不可见的
语法:
id理解为数据库的主键
POST /索引库名/_doc/文档id |
示例:
POST /heima/_doc/1 |
查询
根据rest风格,新增是post,查询应该是get,不过查询一般都需要条件,这里我们把文档id带上。
语法:
GET /{索引库名称}/_doc/{id} |
示例:
GET /heima/_doc/1 |
删除
删除使用DELETE请求,同样,需要根据id进行删除:
语法:
DELETE /{索引库名}/_doc/id值 |
示例:
DELETE /heima/_doc/1 |
修改
全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
语法:
PUT /{索引库名}/_doc/文档id |
示例:
PUT /heima/_doc/1 |
由于id为1的文档已经被删除,所以第一次执行时,得到的反馈是created:
所以如果执行第2次时,得到的反馈则是updated:
局部修改
局部修改是只修改指定id匹配的文档中的部分字段。
语法:
POST /{索引库名}/_update/文档id |
示例:
POST /heima/_update/1 |
7. 批处理
批处理采用POST请求,基本语法如下:
POST _bulk |
其中:
index代表新增操作_index:指定索引库名_id指定要操作的文档id{ "field1" : "value1" }:则是要新增的文档内容
delete代表删除操作_index:指定索引库名_id指定要操作的文档id
update代表更新操作_index:指定索引库名_id指定要操作的文档id{ "doc" : {"field2" : "value2"} }:要更新的文档字段
示例,批量新增:
POST /_bulk |
批量删除:
POST /_bulk |
8. JavaRestClient
8.1 导入客户端
在elasticsearch提供的API中,与elasticsearch一切交互都封装在一个名为RestHighLevelClient的类中,必须先完成这个对象的初始化,建立与elasticsearch的连接。
分为三步:
1)在item-service模块中引入es的RestHighLevelClient依赖:
<dependency> |
2)因为SpringBoot默认的ES版本是7.17.10,所以我们需要覆盖默认的ES版本:
<properties> |
3)初始化RestHighLevelClient:
初始化的代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( |
8.1.1 编写简单测试类
package com.hmall.item.es; |
client=org.elasticsearch.client.RestHighLevelClient@12c7a01b |
8.2 索引库操作
package com.hmall.item.es; |

8.3 文档操作
新增
从MySQL中新增数据到elastic
/** |
有@Autowired private MyService myService;
是想要SpringBean 对象@SpringBootTest 注解通常用于集成测试中,它会启动整个 Spring 容器,以便可以注入 Spring 管理的 Bean。如果不是测试类,使用 SpringApplication.run() 启动 Spring Boot 应用
在
hm-service模块的com.hmall.item.domain.dto包中定义一个新的DTO
新增结果
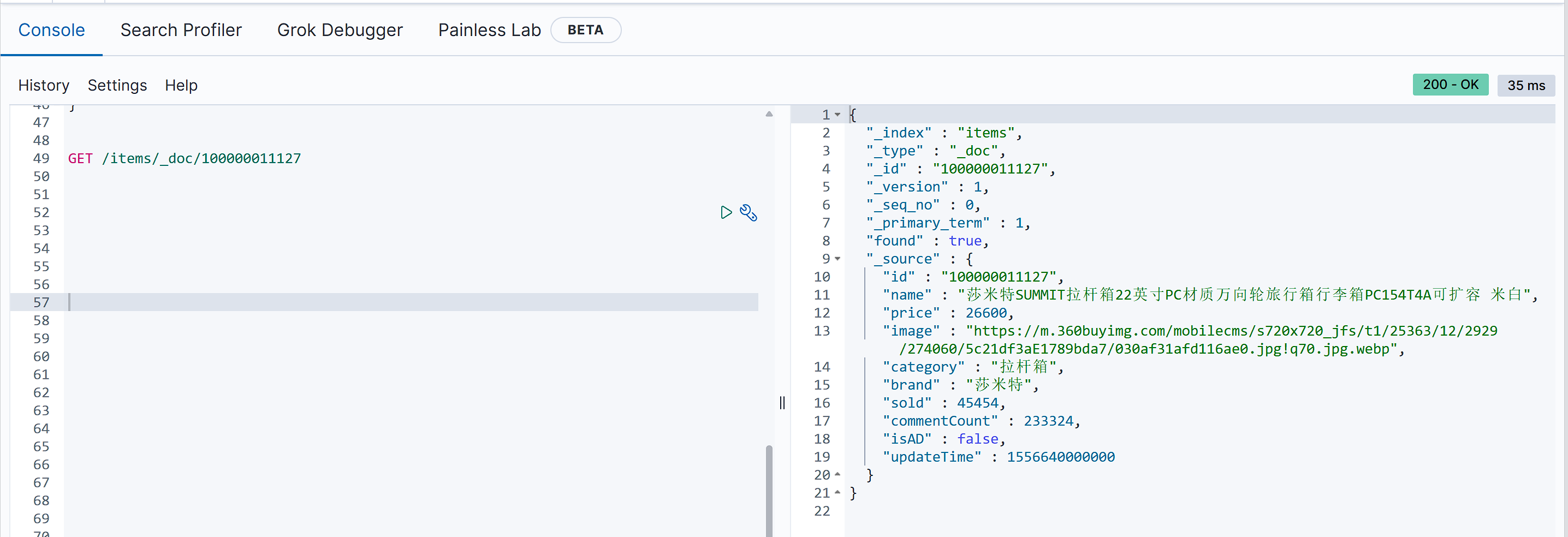
查询
|
结果
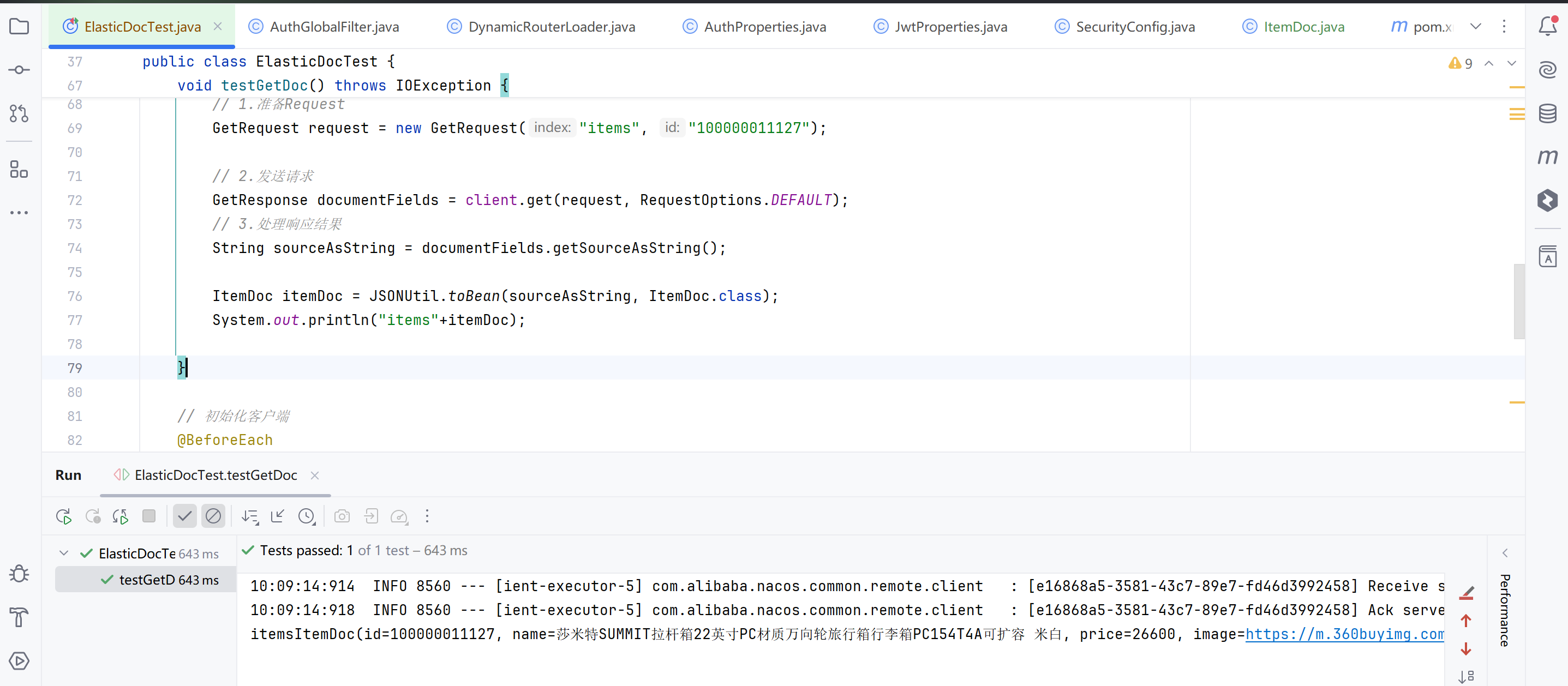
删除
|
更新
// 更新 |
批处理
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建Request,但这次用的是
BulkRequest - 准备请求参数
- 发送请求,这次要用到
client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个
IndexRequest请求,然后封装到BulkRequest中,一起发出。 - 批量删除,就是创建N个
DeleteRequest请求,然后封装到BulkRequest,一起发出
因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:

可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。示例:
|
完整代码
// 批处理 |
八. Elasticsearch 02
Elasticsearch的查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。

8.1 DSL查询
1. 入门
我们依然在Kibana的DevTools中学习查询的DSL语法。首先来看查询的语法结构:
GET /{索引库名}/_search |
说明:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改
例如,我们以最简单的无条件查询为例,无条件查询的类型是:match_all,因此其查询语句如下:
GET /items/_search |
由于match_all无条件,所以条件位置不写即可。
2. 叶子查询
叶子查询可分为:
- 全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
match:multi_match
- 精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
idstermrange
- 地理坐标查询:用于搜索地理位置,搜索方式很多,例如:
geo_bounding_box:按矩形搜索geo_distance:按点和半径搜索
- …略
2.1 全文检索查询

GET /{索引库名}/_search |
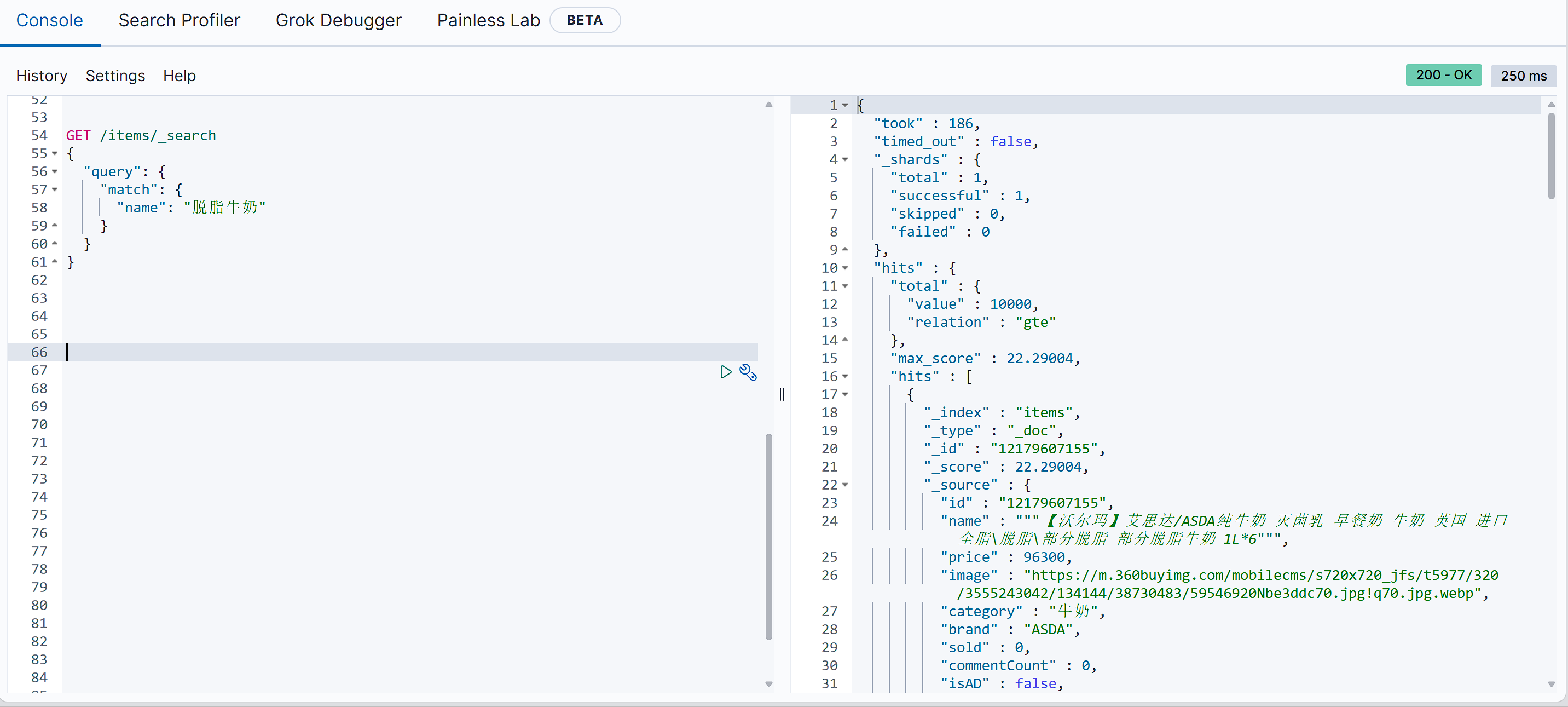
与match类似的还有multi_match,区别在于可以同时对多个字段搜索,而且多个字段都要满足,语法示例:
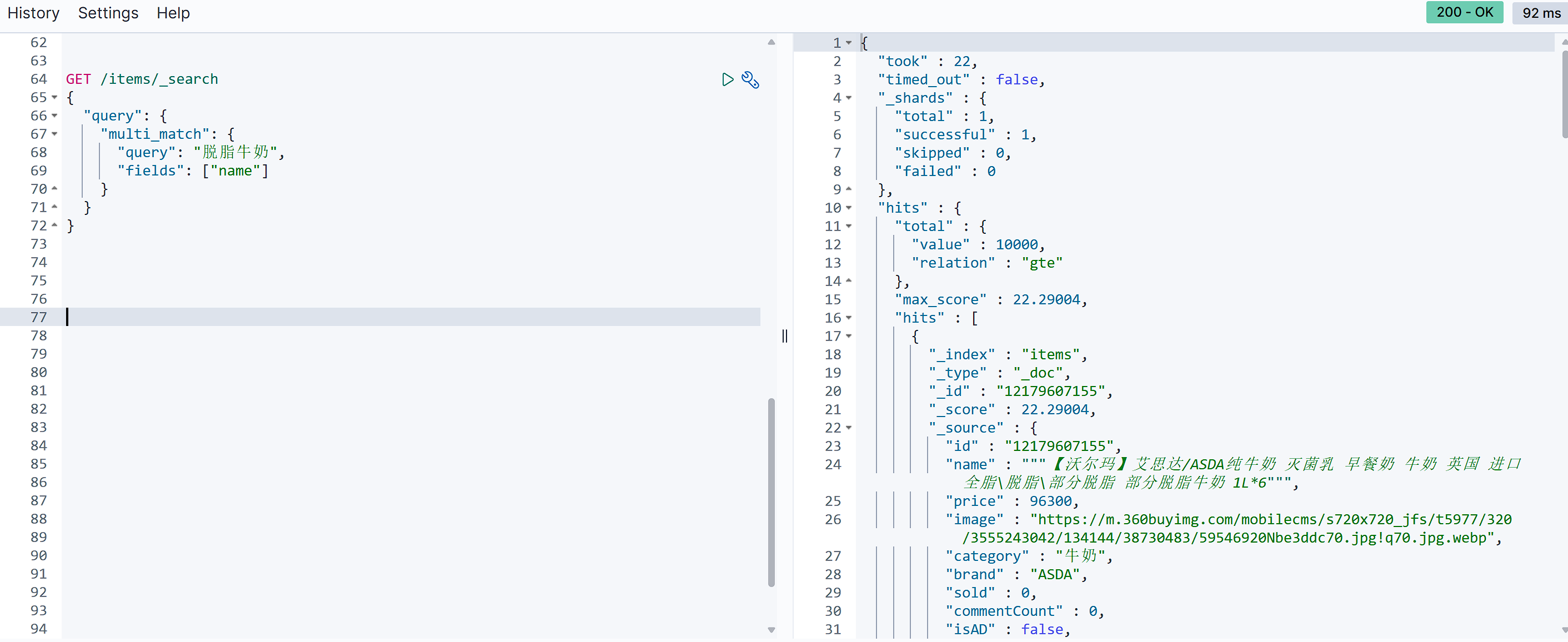
GET /{索引库名}/_search |
参与查询字段越多,查询性能就越差,可以使用copy_to将多个字段拷贝到一个字段中
相关度评分是基于BM25(Best Matching 25)算法来计算的,这是一种改进的TF-IDF(Term Frequency-Inverse Document Frequency)算法。
2.2 精确查询
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。因此推荐查找keyword、数值、日期、boolean类型的字段。例如:
- id
- price
- 城市
- 地名
- 人名
等等,作为一个整体才有含义的字段。
以term查询为例,其语法如下:
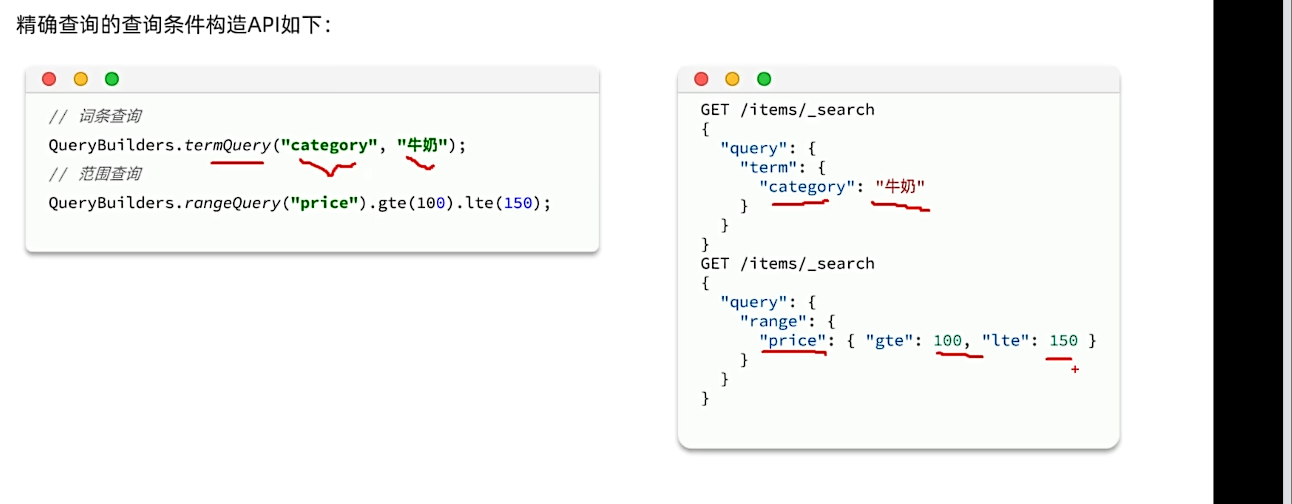
GET /{索引库名}/_search |

因为这里的brand是text类型的会被分词,如果直接匹配就匹配不上了,所以加了keyword
range范围查询
range是范围查询,对于范围筛选的关键字有:
gte:大于等于gt:大于lte:小于等于lt:小于
GET /items/_search |

Ids根据id查询
GET /items/_search |
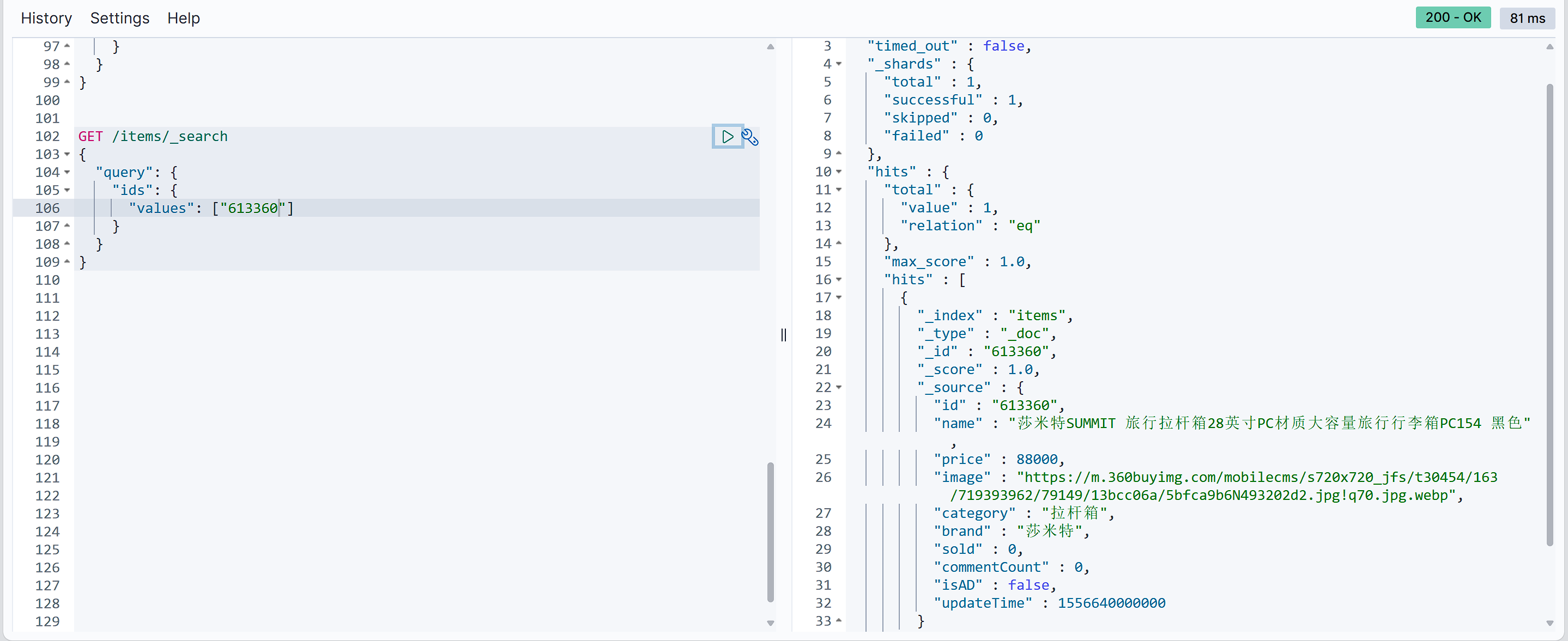
match和multi_match的区别是什么?
match:根据一个字段查询
multi_match:根据多个字段查询,参与查询字段越多,查询性能越差
精确查询常见的有哪些?
- term查询:根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段
- range查询:根据数值范围查询,可以是数值、日期的范围
3. 复合查询
复合查询大致可以分为两类:
- 第一类:基于逻辑运算组合叶子查询,实现组合条件,例如
- bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
3.1 bool查询
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
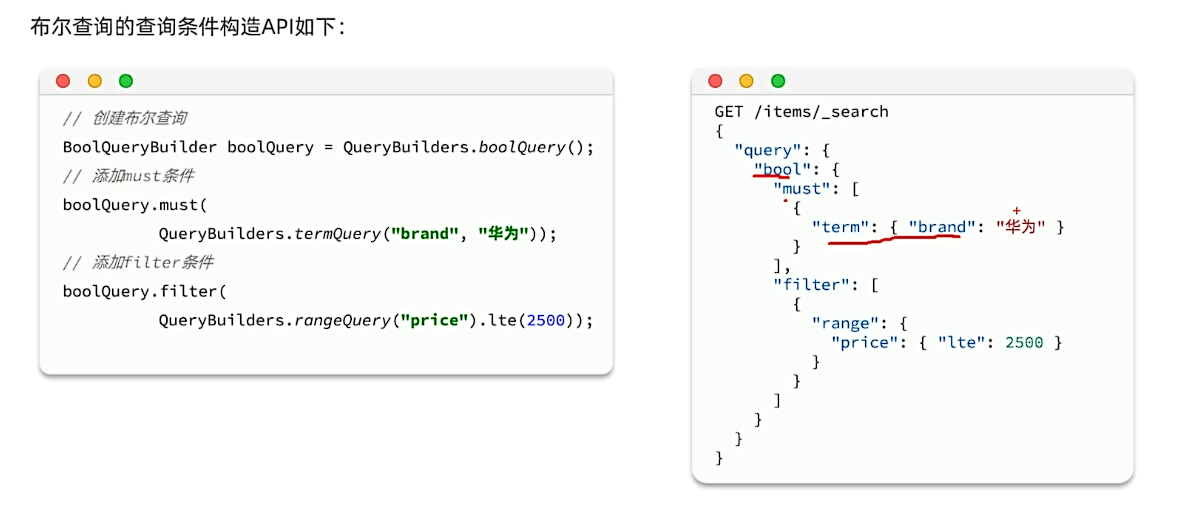
bool查询的语法如下:
GET /items/_search |
出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
例如:
查询智能手机品牌华为
|
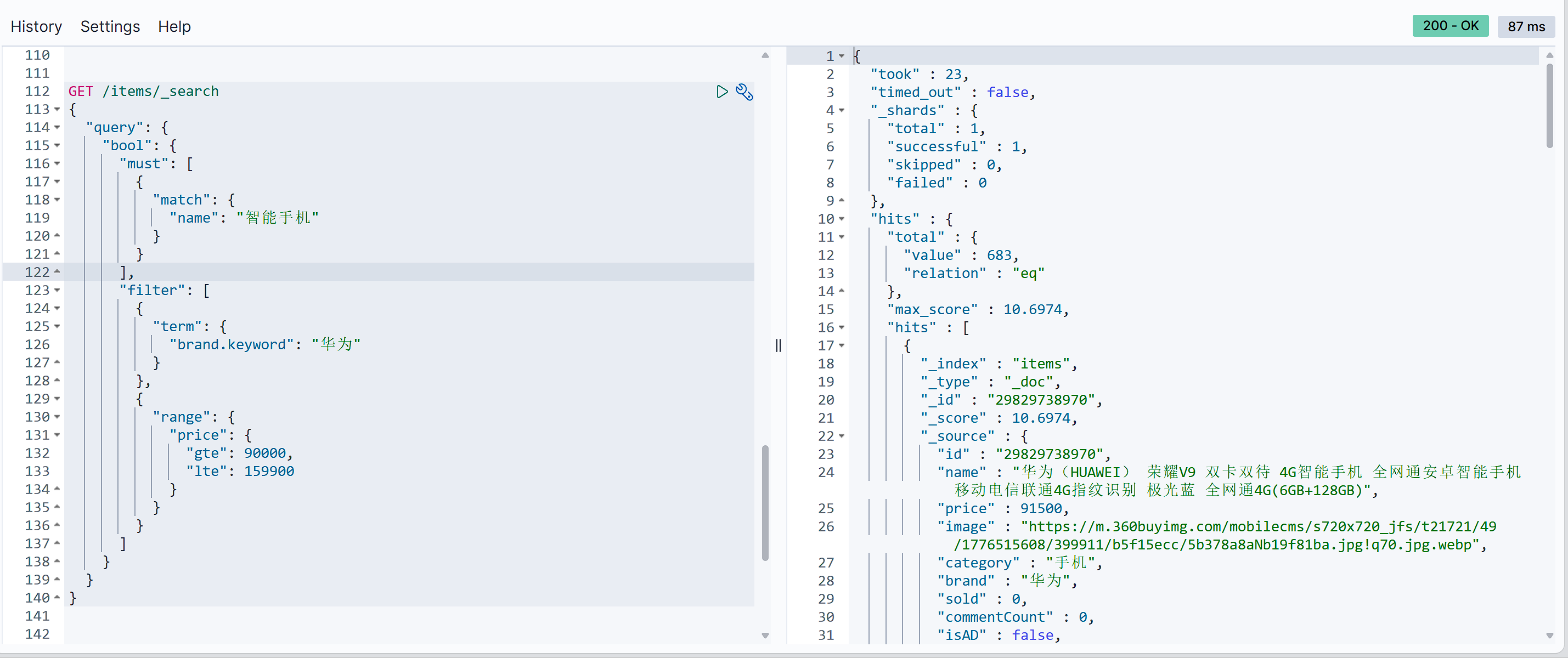
4. 排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。不过分词字段无法排序,能参与排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
语法说明:
GET /indexName/_search |
示例
GET /items/_search |
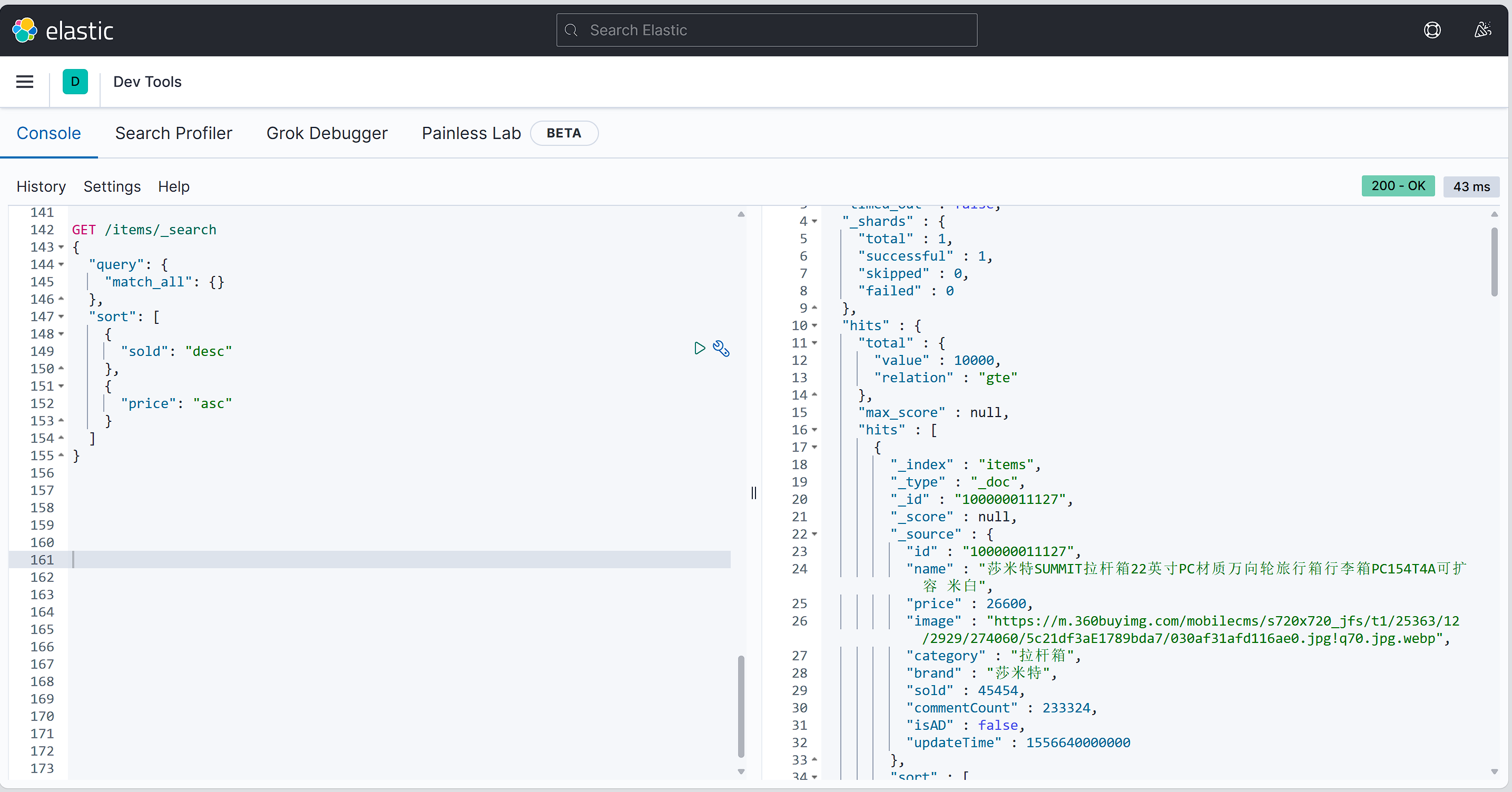
5. 分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
from:从第几个文档开始size:总共查询几个文档
类似于mysql中的limit ?, ?
语法如下:
GET /items/_search |
例如:
GET /items/_search |
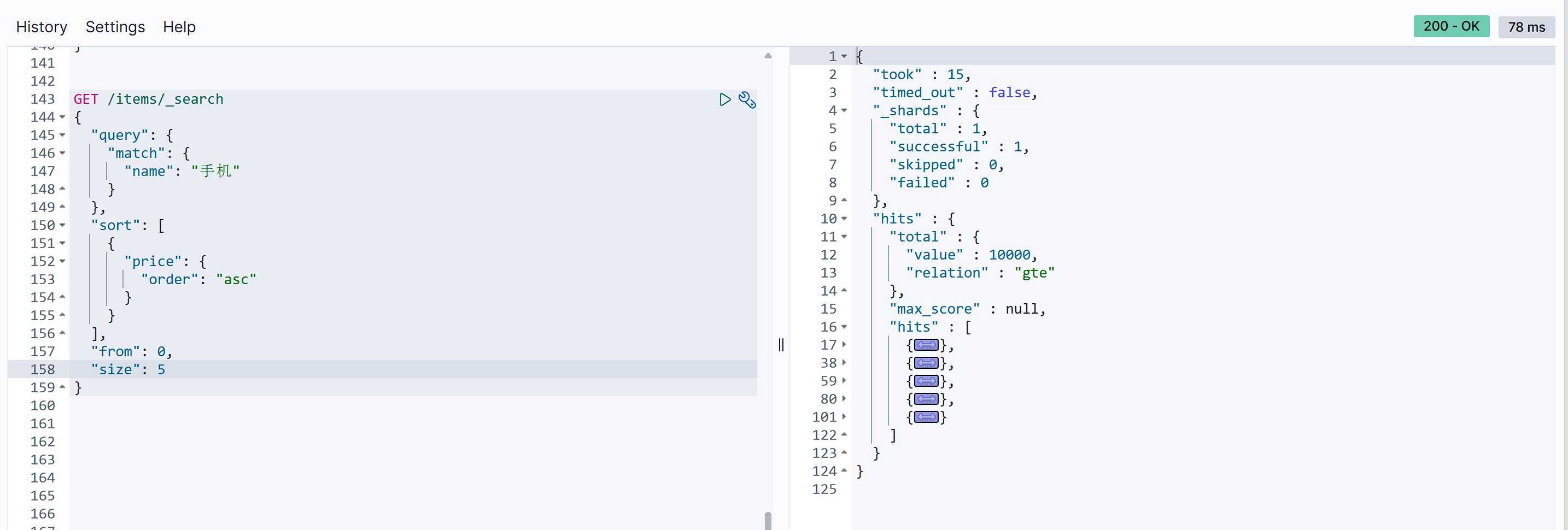
深度分页
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
Elasticsearch 的索引由多个不可变的分段(Segment) 组成,每个分段独立存储数据。文档按写入顺序存储在分段内,类似数组结构。通过内部文档 ID(Lucene 的 doc_id)可直接计算偏移量,实现快速随机访问。(POST /index/_doc)就会自动创建id,(POST /index/_doc/{id})就是手动创建id,前面我们通过java的es客户端是后者的方式)
但是简单分页查询的问题在于,排序并不一定总是按文档id顺序排序,而是常常会按某些关键字进行排序(例如下方,但下方并未说明,实际有“sort“条件但没有“query“条件时,算分均为null,此时按文档id升序排列。题外话:如果只有“from“和“size“,不显式指定“sort“排序条件时,es默认会将搜索结果按算分降序排列;但同时没有“query“条件时,那么默认“query“就是match_all,所有算分都是1.0,此时退化为按_doc升序默认排序),所以会导致排序后文档id分散,从而无法依靠id顺序如同数组一般随机访问,而是如同链表一般顺序访问。
而分页条件(from、size)越大,查询内容也就越多(查询内容当然存在内存中,es是一个java项目,例如找出前10000个数据放在内存里,最后遍历到第9990-10000的数据),数据过多就会导致oom。这里“深度分页”解决的就是分页数据量过于庞大的问题。

from+size = 页码 * size
针对深度分页,elasticsearch提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
https://blog.csdn.net/weixin_47762494/article/details/145763668?spm=1001.2014.3001.5501
假设你在看一本书,你已经翻到某一页(例如第10页),然后你想继续看第11页。search_after就像是“给你上一页的最后一行文字”,让你知道接下来你应该从哪里开始读,而不是从头开始翻书(就像from那样跳过很多页)

6. 高亮显示
事实上elasticsearch已经提供了给搜索关键字加标签的语法,无需我们自己编码。
基本语法如下:
GET /{索引库名}/_search |
注意:
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match - 参与高亮的字段必须是
text类型的字段 - 默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
示例
|

8.2 RestClient 查询
文档的查询依然使用昨天学习的 RestHighLevelClient对象,查询的基本步骤如下:
- 1)创建
request对象,这次是搜索,所以是SearchRequest - 2)准备请求参数,也就是查询DSL对应的JSON参数
- 3)发起请求
- 4)解析响应,响应结果相对复杂,需要逐层解析
1. 查询所有
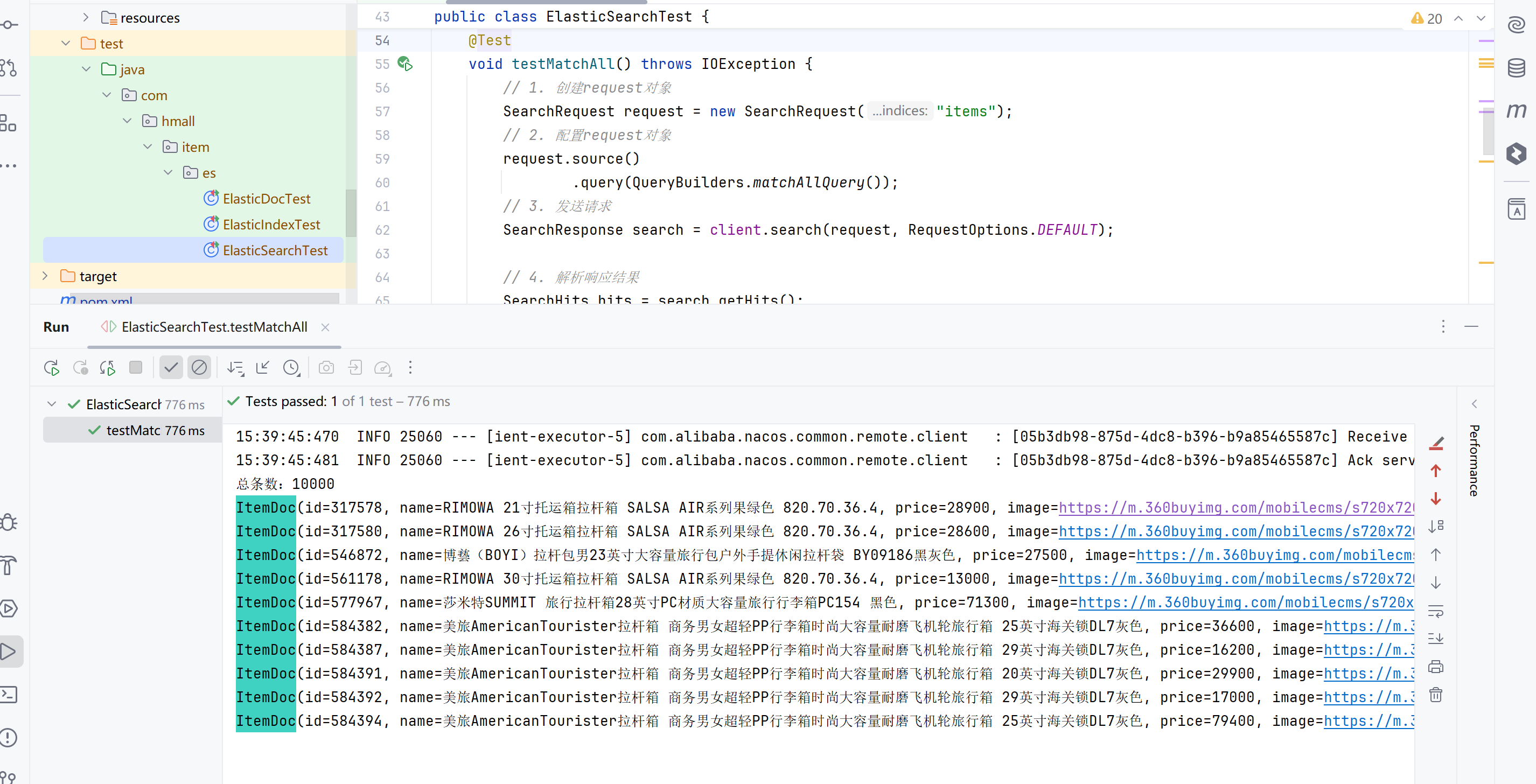
查询所有
public class ElasticSearchTest { |
2. 构建条件查询
全文检索查询

精确查询
布尔查询
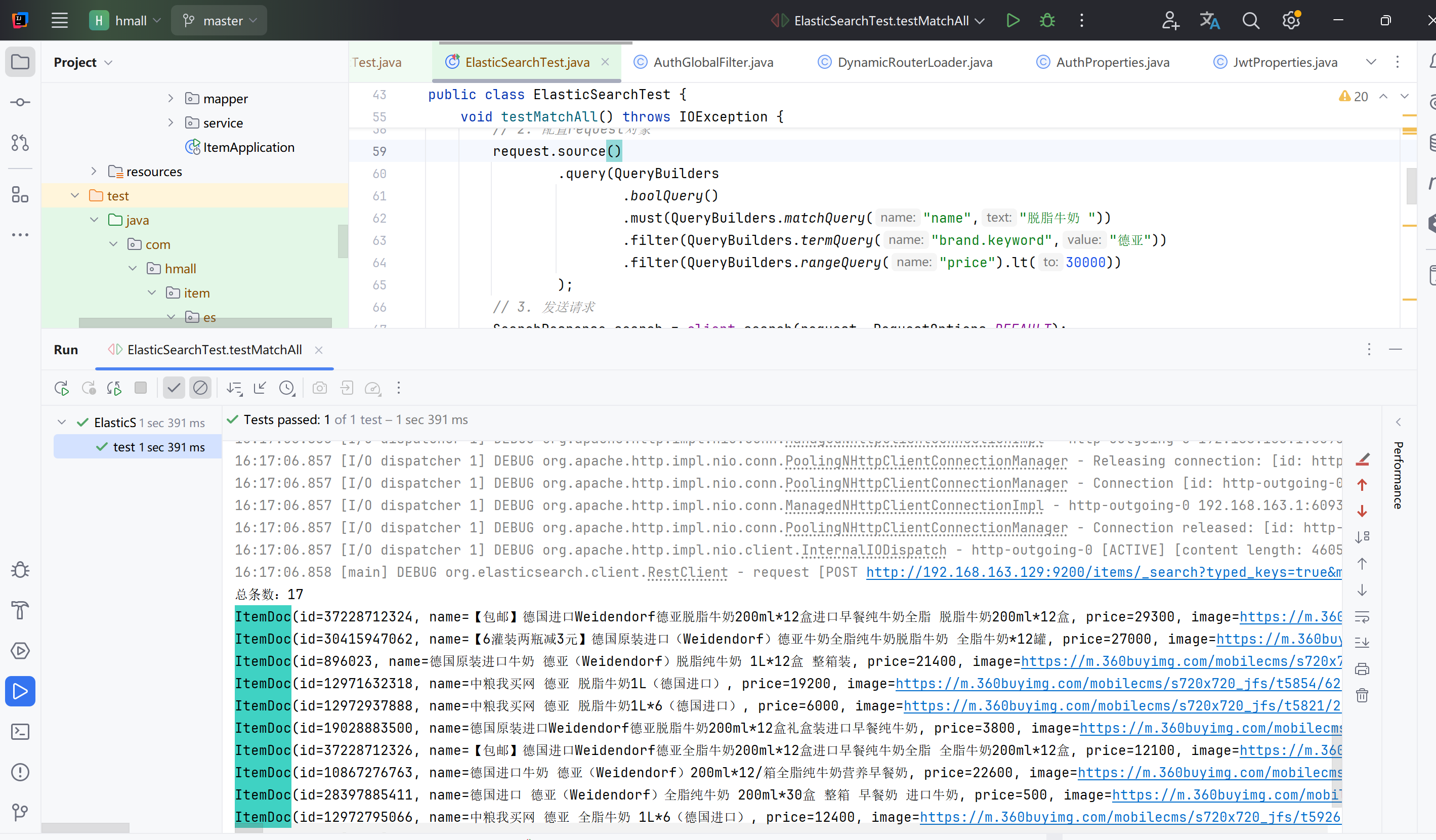
示例
搜索关键字脱脂牛奶,品牌德亚,价格低于300
public class ElasticSearchTest { |
3. 排序和分页

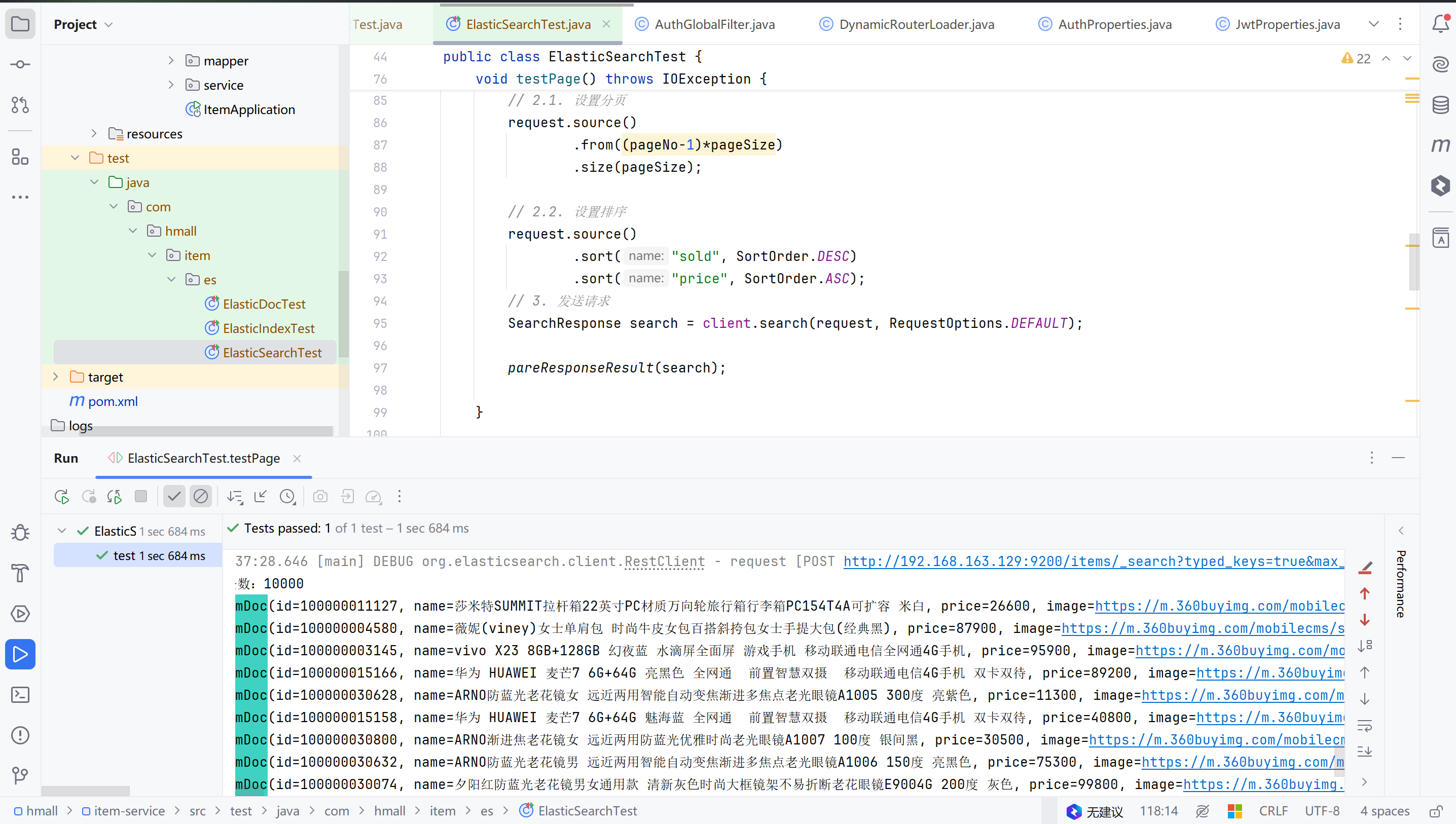
示例
// 分页 |
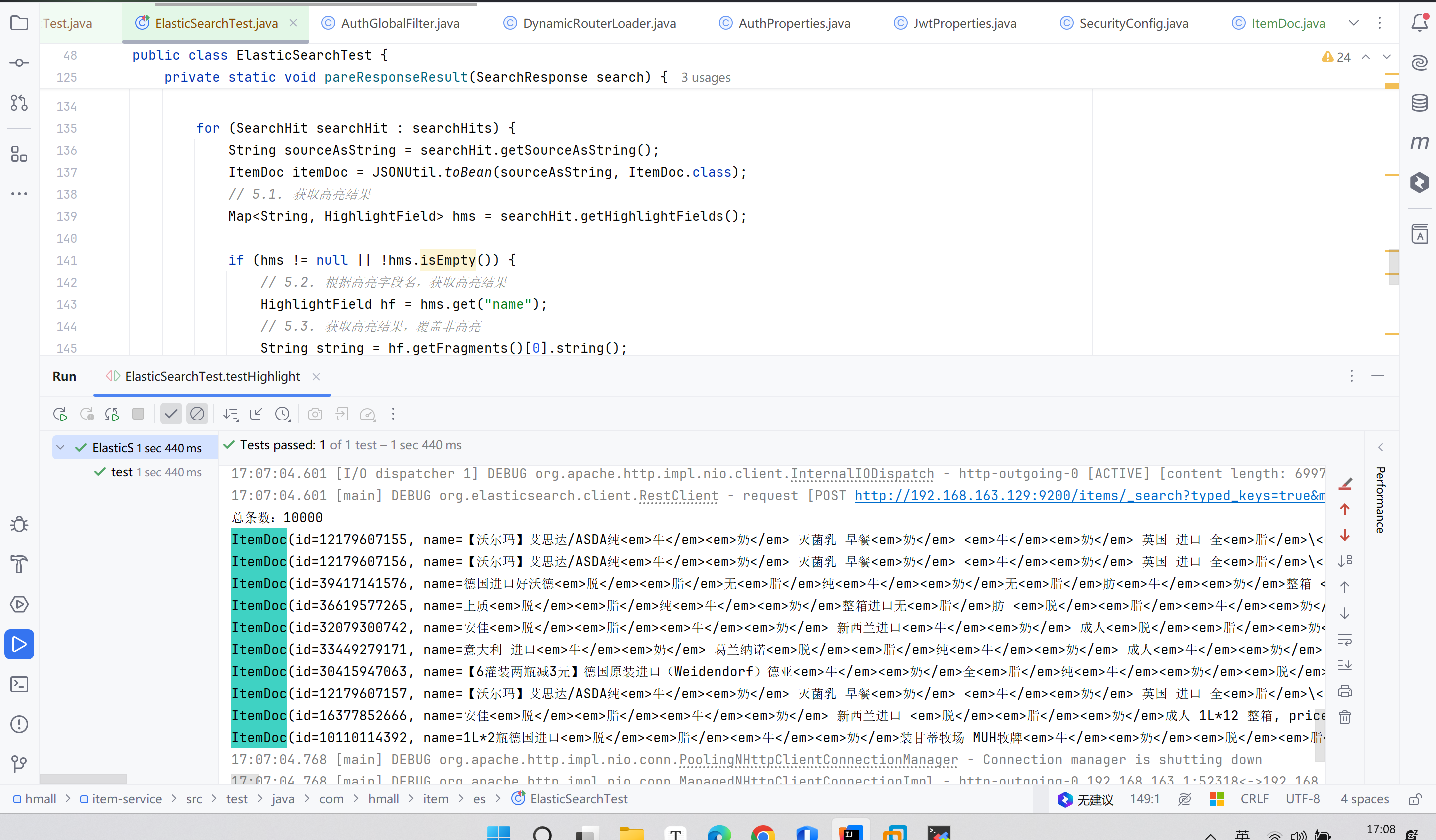
4. 高亮显示
// 高亮 |
8.3 数据聚合
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
- **桶(
Bucket)**聚合:用来对文档做分组 TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组- **度量(
Metric)**聚合:用以计算一些值,比如:最大值、最小值、平均值等 Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等- **管道(`pipeline)**聚合:其它聚合的结果为基础做进一步运算
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型

下面俩小人怎么盯着劳资看
1. DSL聚合
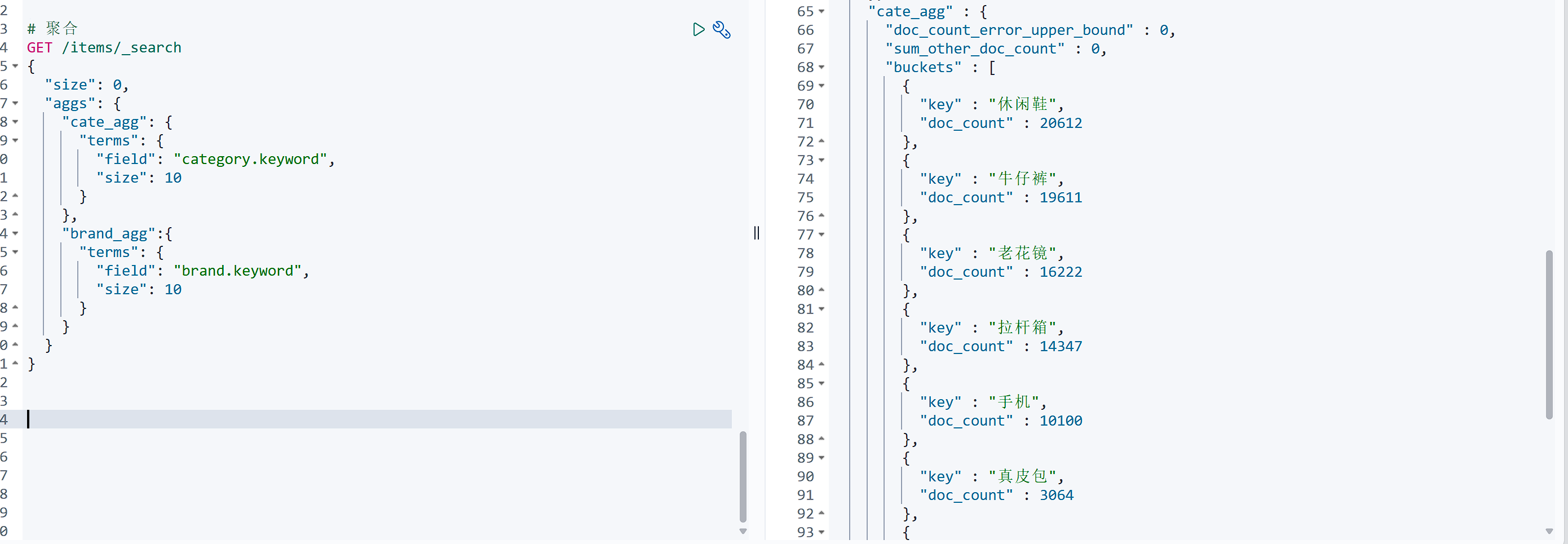
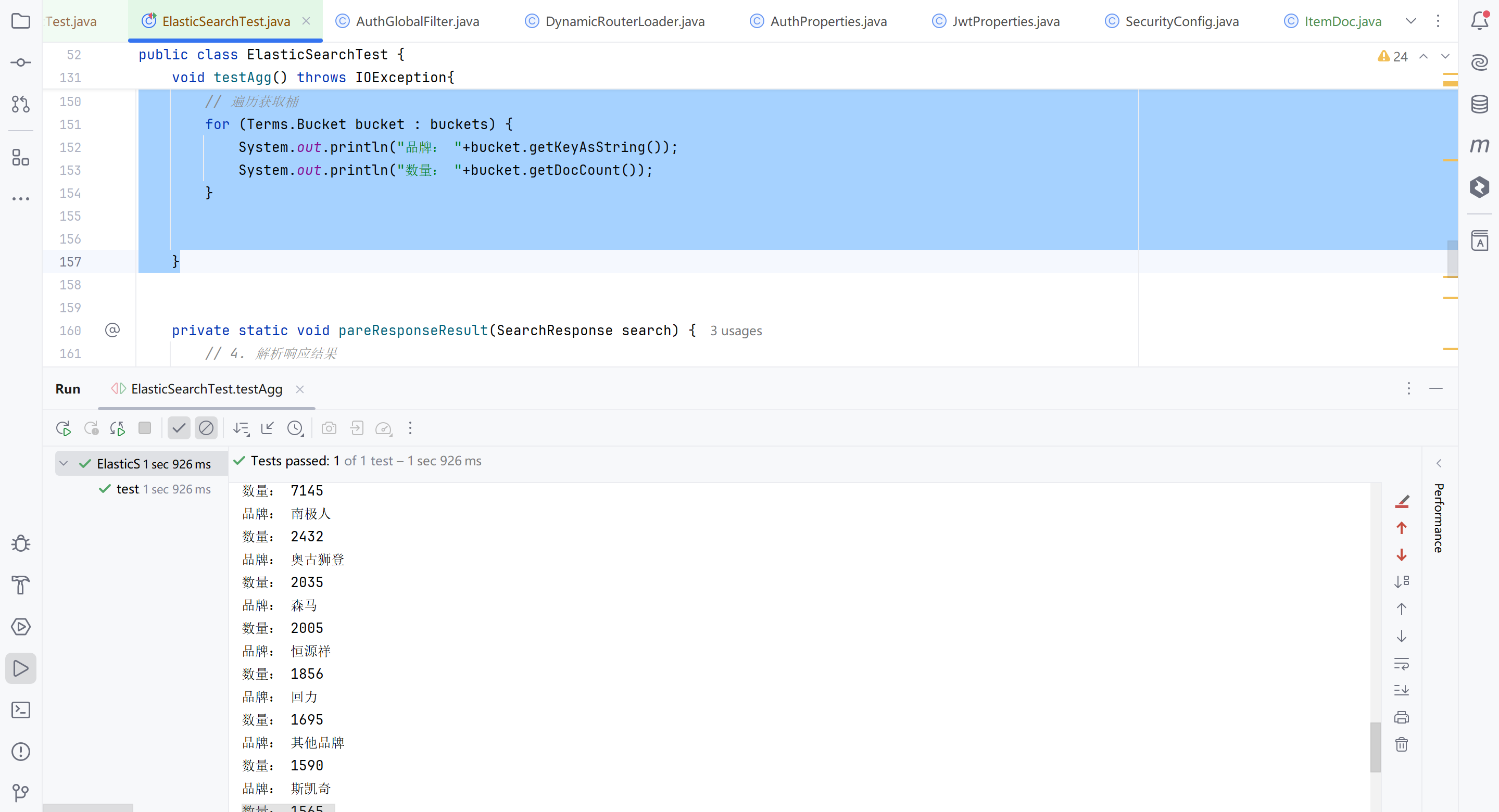
例如我们要统计所有商品中共有哪些商品分类,其实就是以分类(category)字段对数据分组。category值一样的放在同一组,属于Bucket聚合中的Term聚合。
基本语法如下:
GET /items/_search |
Bucket聚合
# 聚合 |
带条件的聚合
# 带条件的聚合 |

Metric聚合
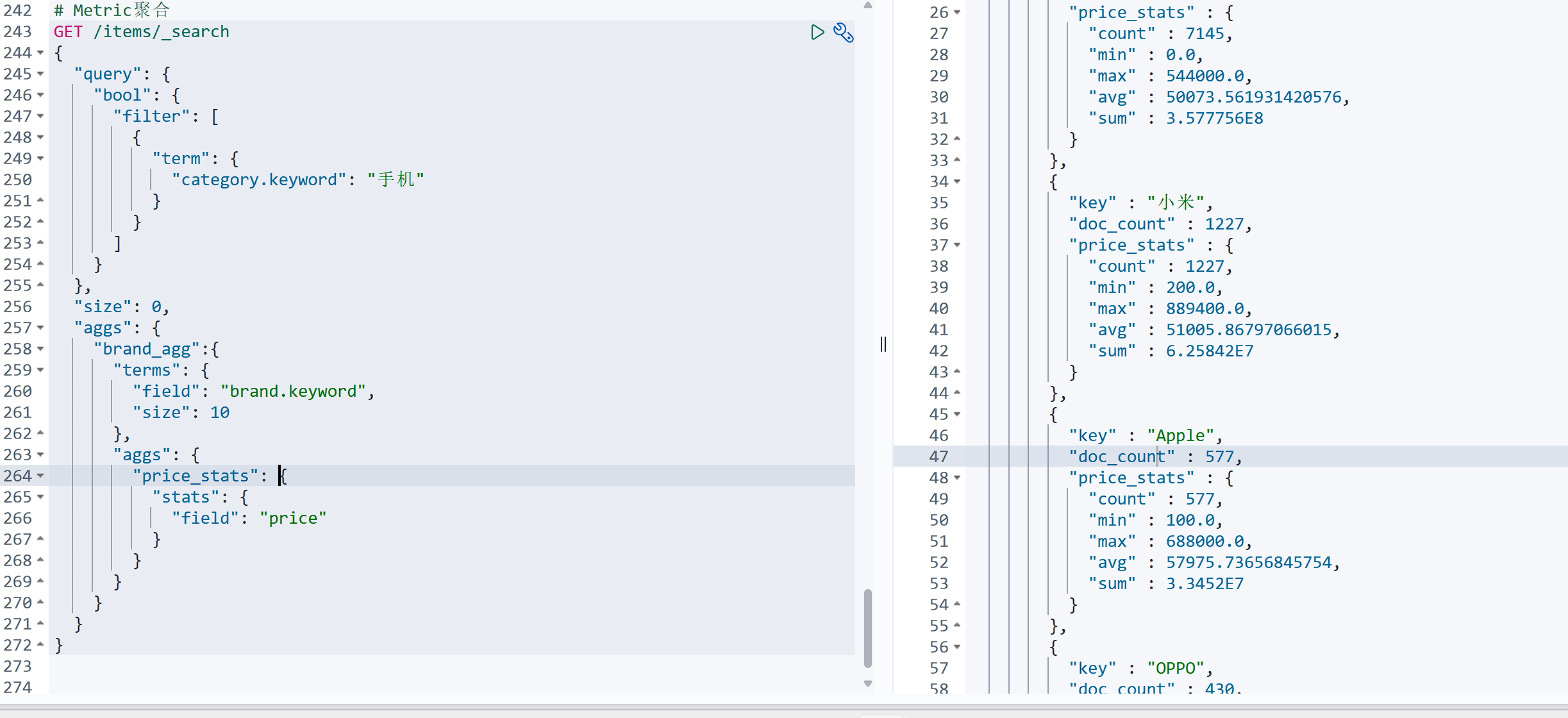
上节课,我们统计了价格高于3000的手机品牌,形成了一个个桶。现在我们需要对桶内的商品做运算,获取每个品牌价格的最小值、最大值、平均值。
这就要用到Metric聚合了,例如stat聚合,就可以同时获取min、max、avg等结果。
# Metric聚合 |
2. RestClient聚合
|
九、面试部分
详情参照站内另外一篇文章面试模块





